Low level benchmarking on Mac OS X and Linux
Lmbench 3.0 provides a suite of micro-benchmarks that measure the bottlenecks at the Unix operating system and CPU level. We were not able to install Yellow Dog Linux on the 2.7 GHz Apple machine, although the paper specs (excluding the CPU) were exactly the same as our 2.5 GHz PowerMac. Some small chipset tweak or firmware change is probably the cause of our YDL installation failure on the newest and latest Apple PowerMac.So, we'll give Mac OS X a small advantage by running it on the 2.7 GHz and Linux on the 2.5 GHz machine. Frankly, I don't care much about an 8% clock difference, as the main goal is to find out why MySQL runs between 5 and 8 times slower on Mac OS X!
The Unix process/thread creation is called "forking" as a copy of the calling process is made. lmbench "fork" measures simple process creation by creating a process and immediately exiting the child process. The parent process waits for the child process to exit. lmbench "exec" measures the time to create a completely new process, while "sh" measures the time to start a new process and run a little program via /bin/sh (complicated new process creation).
Everything is expressed in micro seconds, lower is better.
| Host | OS | Mhz | fork hndl |
exec proc |
sh proc |
| G5 2.7 GHz | Darwin | 2700 | 659 | 2308 | 4960 |
| G5 2.5 GHz | Linux | 2500 | 182 | 748 | 2259 |
| Xeon 3.6 GHz | Linux | 3585 | 158 | 467 | 2688 |
| Opteron 850 | Linux | 2404 | 125 | 471 | 2393 |
In the previous article, I wrote: "Mac OS X is incredibly slow - between 2 and 5(!) times slower - in creating new threads, as it doesn't use kernelthreads, and has to go through extra layers (wrappers)"
Readers pointed out that there were two errors in this sentence. The first one is that Mac OS X does use kernelthreads, and this is completely true. My confusion came from the fact that FreeBSD 4.x and older - which was part of the OS X kernel until Tiger came along - did not implement kernelthreads; rather, only userthreads. It was one of the reasons why MySQL ran badly on FreeBSD 4.x and older. In the case of userthreads, it is not the kernel that manages the threads, but an application running on top of the kernel in userspace.
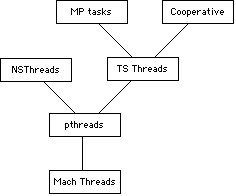
Mac OS X thread layering hierarchy (Courtesy: Apple)[1]
From Apple:
"POSIX thread (commonly referred to as a "pthread") is a lightweight wrapper around a Mach thread that enables it to be used by user-level processes. POSIX threads are the basis for all of the application-level threads."Readers also pointed out that LMBench uses "fork", which is the way to create a process and not threads in all Unix variants, including Mac OS X and Linux. I fully agree, but does this mean that the benchmark tells us nothing about the way that the OS handles threading? The relation between a low number in this particular Lmbench benchmark and a slow creating of threads may or may not be the answer, but it does give us some indication of a performance issue. Allow me to explain.
In the Unix world, threads are often described as lightweight processes. A thread is a sequential flow of control within a program, whereas a process is one or more threads plus its own (virtual) address space. Threads share the same address space and thus, share memory and can exchange information very quickly. However, it is important to understand that threads and processes are not completely different, but they are related to each other.
In the case of Linux, creating a thread is very similar to creating a process. In fact, you use the same procedure, only with different flags or parameters. Linux implements all threads as if they were standard processes. You create a new thread with the clone() call, and the necessary flags, which describe the resources (memory) to be shared. The process creation is done with fork(), but fork() is nothing less than a clone() without the flags that describe the resources that must be shared. So, if you test fork() on Linux, you also get a rough idea of how fast threads are created.
What about Mac OS X? Well, when the Mach kernel is asked to create a Unix process (fork()), the mach kernel creates a task (which describes the resources available) and one thread. So, thread creation time is included in the fork () benchmark of Lmbench.
What can we conclude from this? First, the above tables demonstrate clearly that the creation of UNIX processes is much slower on MAC OS X, and the G5, the CPU, is not to blame. In the first test, the G5 2.5 GHz running Linux is only slightly slower than a Pentium 4 at 3.6 GHz. The third test shows that the G5 is even capable of outperforming the other CPUs, which points towards Mac OS X being the problem here. Even with a faster CPU, the OS X scores are all slower than the Linux scores on the G5.
Does this give us an idea of why MySQL performs so badly? Unfortunately, it makes us suspect that not only process, but thread creation is also slow. We can suspect it, since the process creation, which includes the creation of one thread, takes up to 5 times longer. We can't prove it, as the thread creation time is a small part of the total benchmark time, and we are not sure that the time to create a thread compared to the total time is the same proportionally on both Mac OS X and Linux. LMBench gives us a rough indication that we might be right, but it doesn't give us cold hard facts. We need to look elsewhere for those.
Interprocess Communication (IPC) and Signaling
Signals allow processes (and thus threads) to interrupt other processes. Although MySQL is only one process, it must cooperate with other process via IPC. Benchmarking signal and interprocess communication latency allows to us to understand how quickly the MySQL process can cooperate with other processes and the Operating System. Contrary to workstation and gaming applications, access to the operating system and other processes is critical for database server performance. For example, our client in our database testing setup sends the queries via a Gigabit Ethernet connection (hardware - Layer 1) and via TCP-IP (Network stack Layer 2-4) to the server.Larry McVoy (SGI) and Carl Staelin (HP) on signaling:
"Lmbench measures both signal installation and signal dispatching in two separate loops, within the context of one process. It measures signal handling by installing a signal handler and then repeatedly sending itself the signal."All numbers are expressed in micro seconds; thus, lower is better.
| Host | OS | Mhz | Null | null call |
open I/O |
stat | slct clos |
sig TCP |
sig inst |
| G5 2.7 GHz | Darwin | 2700 | 1.13 | 1.91 | 4.64 | 8.6 | 21.9 | 1.67 | 6.2 |
| G5 2.5 GHz | Linux | 2500 | 0.14 | 0.26 | 3.41 | 4.16 | 18.9 | 0.38 | 1.9 |
| Xeon 3.6 GHz | Linux | 3585 | 0.19 | 0.25 | 2.3 | 2.88 | 9.0 | 0.28 | 2.7 |
| Opteron 850 | Linux | 2404 | 0.08 | 0.17 | 2.11 | 2.69 | 12.4 | 0.17 | 1.14 |
Signaling needs significantly more time in Mac OS X (Darwin) than on Linux. The processor plays a minor role: the Opteron at 2.4 GHz is a bit faster than the Xeon 3.6 GHz running exactly the same (x86) code. However, it is clear that the operating system plays a much bigger role: a 2.5 GHz G5 running Linux easily beats the identical system with a 2.7 GHz G5 running Mac OS X. Despite the FreeBSD heritage, the TCP signals are very slow (4 times slower!) on Mac OS X.
The slower signaling results likely contribute to the overall unimpressive MySQL performance. There are still other factors that also play a part. Let us check out Inter Process Communication (IPC).
| Host | OS | Pipe | AF UNIX |
UDP | TCP | TCP conn |
| G5 2.7 GHz | Darwin | 9.496 | 13.1 | 34.8 | 44.5 | 61 |
| G5 2.5 GHz | Linux | 11.6 | 16.4 | 19.1 | 19.6 | 34 |
| Xeon 3.6 GHz | Linux | 9.909 | 19.0 | 16.0 | 19.3 | 40 |
| Opteron 850 | Linux | 7.645 | 11.2 | 14.2 | 15.9 | 24 |
As TCP is connection based, you get Synchronize (SYN) and Acknowledgement (ACK) messages to establish a reliable connection, before any data can be transferred. Lmbench measures this startup time (TCP conn). Notice how the G5 performs this task quite quickly with Linux, but much slower with Mac OS X. The latency to connect to a TCP server is also measured (TCP) and Mac OS X is measured to be more than twice as slow compared to the Linux based machines, including the same G5 machine. So, although network bandwidth might not be a problem for our benchmark, network latency might have an influence.
Some studies show that there is a direct relationship between these TCP benchmarks and some aspects of Database performance. For example, it was reported that "The TCP latency benchmark is an accurate predictor of the Oracle distributed lock manager's performance." [2]








47 Comments
View All Comments
Gandalf90125 - Friday, September 2, 2005 - link
From the article:"...so it seems that IBM, although slightly late, could have provided everything that Apple needs."
I'd say not everything Apple needs as I suspect the switch to Intel was driven more by marketing than any technical aspect of the IBM vs. the Intel chips.
Illissius - Friday, September 2, 2005 - link
A few notes:- you mention trying a --fast-math option, which I've never heard of... presumably this was a typo for -ffast-math?
- when I tried using -mcpu (which you say you used for YDL) on GCC 3.4, it told me the option had been deprecated, and -mtune has to be used instead (dunno whether it told me this latter part itself or I read it somewhere else, but it's true). I'm not sure whether GCC4 has the same behaviour (I'd think so), whether it still has the intended effect despite the warning, or whether it matters at all.
- was there a reason for using -march on one, and -mcpu/-mtune on the other? (the difference is that -mcpu/-mtune optimize the code for that processor as much as possible while still keeping the code compatible with everything else in the architecture, while -march does the same without care for compatibility -- on x86 at least, not sure whether it's the same on PPC)
- you mention using the same compiler because, err, you wanted to use the same compiler... if this was done in the hopes of it generating code of similar speed for each architecture, though, then your own results show there isn't much point -- seems GCC, 3.3 at least, is much better at generating x86 code than PPC (which isn't surprising, given much more work probably went into it due to the larger userbase). Not saying it was a bad idea to use GCC on both platforms (it's a good one, if for no other reason than most code, on the Linux side at least and OSX itself (not sure about the apps) are compiled with it), just that if the above was the reason, it wasn't a very good one ;).
- Continuing the above, I was a bit surprised at the, *ahem*, noticeable difference in speed between not even two different compilers, but two versions of the same. (I was expecting something like 1-5, maybe 10% difference, not 100). Maybe this could warrant yet another followup article, this time on compilers? :)
Pannenkoek - Friday, September 2, 2005 - link
The reason is that GCC 4.0 incorporated infrastrucure for vector optimization (tree-ssa), which can give, especially in synthetic benchmarks, huge increase in FP performance. GCC can now finally optimize for SSE, Altivec, etc., a reason why in the past optimizing specifically for newer Pentiums did not yield much improvement.Althougn compiler benchmarks would be interesting, I doubt it is a task for Anandtech. Normal desktop users do not have to worry about whether or not their applications are optimized optimally, and any differences between, say GCC and ICC, are small or negligible for ordinary desktop programs. (Multimedia programs often have inline assembly for performance critical parts anyway).
GCC is free, supports about any platform and improves continually while it's already a first class compiler.
javaxman - Friday, September 2, 2005 - link
While I generally love this article, I have to wonder...why not write a simple benchmark for pthread(), if you think that's the bottleneck? Surely it'd be a simple thing to write a page of code which creates a bunch of threads in a loop, then issues a thread count and/or timestamp. It seems like a blindingly obvious test to run. Please run it.
I have to say that I *do* think pthread() is the likely bottleneck, possibly due to BSD4.9-derivative code, but why not test that if we think that's the problem? I understand wanting to see real-world MySQL performance, but if you're trying to find a system-level bottleneck, that's not the right type of testing to do...
Now that I metion it, Darwinx86 vs. BSD 4.9 ( on the same system ) vs. BSD 5.x ( on the same system ) vs. Linux ( on the same system ) would really be a more interesting test at this point... I'm really not caring about PPC these days unless it's an IBM blade system, to be honest... testing an Apple PPC almost seems silly, they'll be gone before too long... Apple's decision to move away from PPC has more to do with *future* chip development than *current* offerings, anyway... Intel and AMD are just putting more R&D into their x86 chips, IBM's not matching it, and Apple knows it...
but even if you are going to look at PPC systems, if you're trying to find a system-level bottleneck, write and run system-level tests... a pthread() test is what is needed here.
rhavenn - Friday, September 2, 2005 - link
If I remember correctly, OS X is forked off of the FreeBSD 4.9 codebase. The 4.x series of BSD always had a crappy threading system and didn't handled threaded apps well at all. I doubt Apple really touched those internals all that much.FreeBSD 5.x has a much better time of it. I'm wondering if the switch back to a Intel platform will make it easier for Apple to integrate the BSD 5.x codebase into their OS? or even if they plan on using the BSD 6.x codebase for a future release? The threading models have vastly improved.
Just a thought :)
JohanAnandtech - Friday, September 2, 2005 - link
http://www.apple.com/education/hed/compsci/tiger.h...">http://www.apple.com/education/hed/compsci/tiger.h... :"FreeBSD 5.0
The upgraded kernel in Tiger, based on mach and FreeBSD, provides optimized resource locking for better scalability across multiple processors, support for 64-bit memory pointers through the System library and standards-based access control lists"
Where did you see FreeBSD 4.9?
mbe - Friday, September 2, 2005 - link
Readers also pointed out that LMBench uses "fork", which is the way to create a process and not threads in all Unix variants, including Mac OS X and Linux. I fully agree, but does this mean that the benchmark tells us nothing about the way that the OS handles threading? The relation between a low number in this particular Lmbench benchmark and a slow creating of threads may or may not be the answer, but it does give us some indication of a performance issue. Allow me to explain...This misses the point, your claim in the last article was that MacOS X used userspace threads. Mentioning that LMbench uses processes still rules out userspace threads having any part to play. This is since processes can't in any meaningful way (short of violating some pretty basic principles) be implemented around userspace threads. The point is that a process is a virtual memory space attached to a main system thread, not a userspace thread which are not normally even considered threads on this level.
This is necessary since the virtual memory attached to the thread has to be managed when doing context switches, and by its very definition userspace code cannot directly touch the memory mappings.
JohanAnandtech - Friday, September 2, 2005 - link
Yes, it could be. The interesting questions are:- Is the only culprit for the 8 time lower performance. Microkernels are reported to be 66 to 5% slower depending on who benchmarked it. But not 8 times slower.
- What makes it still interesting for the apple devs to use it?
I hope Apple will be a bit more keen to defend their product, because their might be interesting technical reasons to keep the Mach kernel.
sdf - Friday, September 2, 2005 - link
Is Mac OS X really a microkernel? I understood it to be designed to function as a microkernel, but compiled and shipped as a macrokernel for performance reasons.JohanAnandtech - Sunday, September 4, 2005 - link
I am sorry if I wasn't clear. As I state in the article clearly: Mac OS X is ** NOT ** a microkernel, but based on a microkernel as the Mach kernel is burried inside the FreeBSD monolithic kernel.Most of the tasks are done by a FreeBSD alike kernel, but threading is done by the Mach kernel.