Western Digital's Raptors in RAID-0: Are two drives better than one?
by Anand Lal Shimpi on July 1, 2004 12:00 PM EST- Posted in
- Storage
Doubling Theoretical Performance: RAID-0
For those of you who are already familiar with RAID and how it works, go ahead and skip to the benchmarks; these next two pages are designed to serve as brief introductions to the two most common forms of RAID on the desktop: RAID-0 and RAID-1.Otherwise known as striping, RAID-0 is the only performance-enhancing form of RAID that we'll be talking about in this article. The premise behind striping is simple. Data being written to a drive is split into "stripes", generally 16 - 256KB in size, with each stripe being written to a different drive in the array. For example, say we were dealing with a 2-drive RAID-0 array with a stripe size of 128KB and we wanted to write 256KB of data; drive 0 would get the first 128KB of data written to it, and drive 1 would get the remaining 128KB.
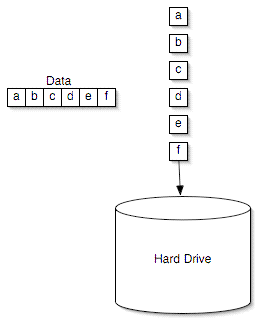
Writing to a single hard disk
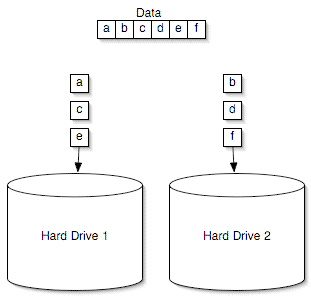
Writing to a two-disk RAID-0 array
Here, you can see that the write performance of RAID-0 can be almost double that of a single drive, since twice as much data gets written at the same time. The higher write performance is obtained at the expense of some controller overhead, since the RAID controller has to handle splitting up data into stripes before sending it to the drives themselves - but with modern day microprocessors being as fast as they are, the overhead is usually thought of as negligible.
Reading works the exact same way, but in reverse. Say that we want to read that same 256KB of data back; we pull one stripe from drive 0 and the other stripe from drive 1. The read is now completed in half the time, theoretically doubling performance.
We are careful to use the word "theoretical" because the performance advantages of RAID-0 disappear quickly if we're not dealing in ideal situations like the ones we just described. If too large of a stripe size is used, then the performance advantages of RAID-0 can be lost, while too small of a stripe size could result in excess overhead, reducing the performance improvement of the striped array.
We have seen in the past that for most desktop applications, the largest stripe size that a desktop RAID controller will offer is usually the best choice for performance. With Intel's ICH5/6, that translates into a 128KB stripe size, which for our comparison is what we decided to go with. The other stripe size options didn't offer any better performance for our desktop test suite.
The main downside to RAID-0, other than cost, is reliability. The size of a RAID-0 array is the sum of all of its members; so, two 100GB drives in a RAID-0 array will give you one array with a 200GB total capacity. Unfortunately, if you lose any one of the drives in the array, all of your data is lost and isn't recoverable. Since two drives are working in tandem and are both necessary to hold your data, you effectively halve the mean time between failure by moving to a two-drive RAID-0 array.








127 Comments
View All Comments
Pumpkinierre - Tuesday, July 6, 2004 - link
Yes that's correct #93. Its the data that counts. The probability of failure of one drive in a Raid0 OR Raid1 over a given period is the same. For two drive Raids, this is double the probability of a single drive failure over the same period if all drives are the same at start of functioning(ie same prob. of failure). In Raid0, probability of LOSS OF DATA corresponds to this doubled single drive failure probability. However, in Raid1, the parameters change. Here, it is the probability of both drives failing on the SAME day in a given period (assuming backup can be completed in a day). This probability is much, much lower than a single HDD or Raid0 data loss probability which is ANY day of a given period.This makes Raid1 the superior Raid for desktop use despite the apparent loss of capacity. With cheap 160GB around, I dont think that's a problem (I got a 120 and its not a third full and I dont backup because I'm lazy and evil). Read requests in Raid1 ought to be faster than Raid0 as variable size virtual striping could be carried out on this raid format. Unfortunately, they used to stripe Raid1 but dont anymore relegating it to the duplexing or mirroring role. Reads apparently are only improved in modern Raid1 when a simultaneous multiple read requests are initiated. Here the controller's extra buffering and ability to read the Raid drives simultaneously at different locations helps out. Once again good for Servers where this is a common requirement but not good for desktops where a striped read would be of far greater use for the speed it brings. We really need Arnie on this one- the broom and the Gatling!
Redundancy means of no further use. A backup drive isnt of no use. So redundancy doesnt mean backup despite how some people use the term to describe Raid1. RAID which stands (I teenk) for Redundant Array of Independent Drives was initially a method of combining older (hence smaller) drives into one big drive. That saved them from being thrown out ie redundant.
mdrohn - Tuesday, July 6, 2004 - link
"Now im sure ill get a roasting from statisticians for not following the rules exactly however as has already been mentioned previously, the notion that by buying 2 of something will halve its chances of enjoying a useful life is just nonsense in individual cases."I'm not a statistician, nor do I play one on TV ;) But similarly to WaltC, you are misunderstanding the fact that in a RAID 0 setup, if ONE member drive fails, the whole array fails IN ITS FUNCTION AS AN ARRAY. What you say is true--the individual life of a single drive is not affected by how many drives you own. But when we are talking about an ARRAY of drives, the operating life of each individual drive in the array is not what is at issue. What is relevant is ARRAY failure, not DRIVE failure.
Let's say you have two drives in a RAID 0 array. One drive fails and the other drive remains in perfect working order. You can reformat the surviving drive and keep using it as long as it continues to function. But you have lost the data on the ENTIRE ARRAY because in RAID 0 there is no redundancy and no backup, and you need both drives working in order to access the data on the array.
mdrohn - Tuesday, July 6, 2004 - link
"Thus the chance of failure for a RAID 0 array is the probability at any given time that *_one_* of the component drives will fail. Assuming all the disks are identical, that chance is equal to the failure probability of one drive, multiplied by the number of drives."OK remind me never to pull formulae out of my butt on a holiday weekend. The actual probability of failure for a RAID 0 array with n members is as follows:
fRAID0 = 1 - (1-fa)(1-fb)(1-fc)...(1-fn)
Where fa, fb, fc, etc are the individual chances of failure for each array member.
The question we are asking, "what is the chance that at least one component drive in a RAID 0 array will fail?" is mathematically identical to asking, "what is the complement (opposite) of the chance that none of the component drives will fail?" The chance that a drive will not fail is the complement of the drive's chance to fail, or 1-fa. The probability that multiple independent events will occur simultaneously ("none of the drives will fail") is the product of those chances. So the probability that multiple independent events will NOT occur simultaneously is the complement of that product.
MadAd - Tuesday, July 6, 2004 - link
Theres lies, damn lies and statistics.The problem with probabilities are that it is a general model to make assumptions and not meant to replicate real world events.
If I get 1 raffle ticket from a raffle of 100, then the probability is 1:100 that I will win. If I buy 2 tickets then thats 2:100 or 1 in 50 chance I will win. However in the worst case there are still 98 other tickets that could be drawn from the hat before one of mine and the 1 in 50 figure will only be realistic if we do lots and lots of raffles and calculate the results as a set.
As far as MTBF is concerned, I would say that a way to more realsticaly plot the likelyhood of faliure of multiple units would be to analyse the values within the range of MTBF results, to 2 s.d. (2 standard deviation measures 95% of results).
E.G. if MTBF is say 60 months, and 95% of the results fall within the 55 to 65 month range then while one drive is likely to last 60 months, either of 2 drives should last at least 57.5 months.
Of course theres a chance that you get a dodgy one that fails in 10 months, that doesnt make it wrong, just that one was one that fell outside the 95% level on the curve.
Now im sure ill get a roasting from statisticians for not following the rules exactly however as has already been mentioned previously, the notion that by buying 2 of something will halve its chances of enjoying a useful life is just nonsense in individual cases.
masher - Tuesday, July 6, 2004 - link
#80 says:> Sending the two seek commands versus one should
> add negligeable time. The actual seeks would be
> done concurrently. The rotational latencies on
> each drive is independent. Therefore the time
> to locate the data should be very close to the
> same as for a single drive.
The latencies for each drive are indepdent, yes...thats the very reason the overall latency is higher. Simple statistics. I'll give you a somewhat simplified explanation of why.
A seek request sent to a single drive finds the disk in a random position, evenly distributed between (best_case_latency) and (worse_case_latency). The mean latency is therefore (best+worse)/2.
Add a second drive to the picture now. On the average, half the time it will be faster than the first drive at a given request, and half the time slower. In the first case, the ARRAY speed is limited by the first drive. In the second case, the array is limited by disk two, which will be randomly distributed between (worst-best)/2 and (worst). The average in this case is therefore (3w-b)/4.
Probability of first case = (1/2)
Probability of second case = (1/2)
Overall mean = (1/2)(w+b)/2 + (1/2)(3w-b)/4 = 5w+b/8.
Assuming best case=0 and worst case=1, you get a mean seek for a single disk of 50%, and a mean seek for a two-disk array of 62%.
mdrohn - Monday, July 5, 2004 - link
WaltC says:"(3)Because RAID 0 employs two drives to form one combined drive, the probability of a RAID 0 drive failure is exactly twice as high as it is for a single drive."
Nighteye2 is correct. The above quote contains a fundamental misstatement and does not correctly represent why RAID 0 multiplies failure rate. WaltC's entire ensuing argument is logically correct, but because it is based on the wrong premise it is not relevant to RAID 0 failure rates. The quote should have read as follows:
"Because RAID 0 employs two drives to form one combined drive, the probability of a RAID 0 *_ARRAY_* failure is exactly twice as high as it is for a single drive."
Having multiple disks in a RAID 0 array does not, as WaltC correctly says, affect an individual disk's chance of failure. But what is relevant to this subject is the failure of the array as a whole. Since in RAID 0 the component drives are linked together without any redundancy or backup, losing one component means that the entire array fails. Thus the chance of failure for a RAID 0 array is the probability at any given time that *_one_* of the component drives will fail. Assuming all the disks are identical, that chance is equal to the failure probability of one drive, multiplied by the number of drives.
Let's take the car analogy. In WaltC's example the two cars are independent, autonomous vehicles. To make it a proper analogy to RAID 0, the two cars would have to be functionally linked so that they operate as one. Let's say you welded the two cars together side by side with steel bars to make one supervehicle. Then if the tires gave out on any one of the two component cars, the entire supervehicle would be stuck.
Nighteye2 - Monday, July 5, 2004 - link
If a single HD has a 50% chance of failing in 5 years, a RAID 0 array with 2 of those drives has a 50% chance of failing in about 4 years, dependant on the distribution of the failure probability function.Nighteye2 - Monday, July 5, 2004 - link
#84, you should study failure theory better. RAID 0 in fact *does* double the chance of failure at any given time. However, this does not mean the MTBF is halved, because disk failure chances are time-dependant, and increase over time.Pumpkinierre - Sunday, July 4, 2004 - link
#84, Even though I agree with some of your comments on the testing, the fact is that Anand was looking at Raid0 from the viewpoint of the desktop user/gamer which is the target audience of the AT website. So he is legitimate in using the tests that are relevant and understood by this target audience for testing HDD performance in both single and RAID combinations rather than specific HDD performance tests. He reaches similar conclusions to storagereviews.com's assessment of RAID use in the desktop environment. However, criticism about failure of testing other controllers (even if limited to onboard controllers) and RAID1 performance I feel are valid.With regards to the likelihood of failure of a component, it must be recognised that all processes in nature are stochastic (probabibility based). This is at the core of quantum mechanics. So all components have an associated probability of failure. That probability is lessened by better manufacturing, quality control, newness etc. but is always present. Naturally, the longer you use the HDD the greater the probability of failure due to wear etc.but it still is possible for it to fail in the first year (and this does happen). The warranty period doesnt mean your HDD is not going to fail, it means they will replace it if it fails. The laws of probability are clear, if you have two components with associated probabilities of failure, you must ADD the two probabilities if you want the probability of ANY ONE of them failing. So, in the case of using two new HDDs Raid O has double the probality of you losing your data to a single HDD.
The consequence of the above (and having lost a HDD at 3yrs and 1day!) means to me, along with many others desktop users who fail to backup (despite having burners) because of laziness, that the oft forgotten Raid1 ought to be the prime candidate for the desktop. Here the probabilities are refined to simultaneous failure of the HDDs on any PARTICULAR day of the 3yr warranty period which is a different probability to failure of EITHER of the discs over the WHOLE 3years. Naturally, when one disc fails in Raid1, the desktop user gets off her butt and backs up on the day prior to any repair. The fact that Raid1 ought to be better at reads than even Raid0 (see my previous posts) is even greater reason to adopt this mode for the desktop (where writes are less used) but has been ignored by the IT community.
TheCimmerian - Sunday, July 4, 2004 - link
Thanks for DV capture stuff, PrinceGaz.