Western Digital's Raptors in RAID-0: Are two drives better than one?
by Anand Lal Shimpi on July 1, 2004 12:00 PM EST- Posted in
- Storage
Pure Hard Disk Performance
To measure "pure" hard disk performance, we took a real world benchmark - in this case, the entire Winstone 2004 suite - and used Intel's IPEAK utility to capture a trace file of all of the IO operations that take place during a single run of Business Winstone 2004 and MCC Winstone 2004. We then use IPEAK to play back the trace, much like a timedemo, on each of the hard drives, which gives us a mean service time in milliseconds; in other words, the average time that each drive took to fulfill each IO operation.In order to make the data more understandable, we report the scores as an average number of IO operations per second so that higher scores translate into better performance.
Keep in mind that these performance scores are best only for comparing pure hard disk performance, and in no way do they reflect the actual real world performance impact of these hard drives.
For descriptions of what the Business and Multimedia Content Creation Winstone 2004 tests consist of, reference those benchmark pages.
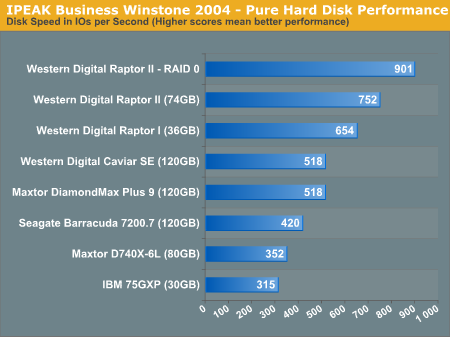
While a score of 901 IO operations per second seems impressive, what's important to note is that two Raptors in RAID-0 only offers 20% more performance than a single Raptor in this purely disk-bound test. We have already seen how aggressive caching, pre-fetching and other such real world elements of modern day computers reduce the impact of hard drive performance on overall system performance. With only a 20% improvement in pure disk performance, this doesn't bode too well for RAID-0 offering much of a real world performance boost.
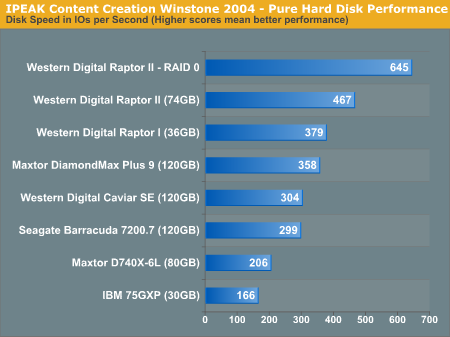
With data from audio editing as well as other more IO intensive tasks, our IPEAK recording of Content Creation Winstone 2004 shows much more potential for RAID-0, with the Raptor RAID-0 array outperforming a single drive by 38%.
Now, it's time to see how these numbers translate into real world performance.








127 Comments
View All Comments
timw - Thursday, July 8, 2004 - link
This isn't really anything new. As someone else mentioned, seek time and cache size with the right firmware optimizations are the most important. RAID 0 won't be able to improve that, and may actually be slower than a single drive in many instances. If you don't believe what Anandtech has to say, take a look at the latest article at storagereview.com.Pumpkinierre - Thursday, July 8, 2004 - link
Wrong again, mdrohn, Australia to be exact, but I was using an Oxford dictionary. The hyperdictionary.com (USA based I think as it advertises cheap dental insurance for US residents) gives redundancy as:Definition: [n] repetition of an act needlessly
[n] the attribute of being superfluous and unneeded; "the use of industrial robots created redundancy among workers"
[n] (electronics) a system design that duplicates components to provide alternatives in case one component fails
[n] repetition of messages to reduce the probability of errors in transmission
Which agrees with both our definitions. Yours is more correct electronically. Hyperdictionary has a more extensive electronic description but doesnt add much more to the above electronic definition:
http://www.hyperdictionary.com/dictionary/redundan...
I'm at odds with that electronic meaning of redundancy. After all the language came before the electronics.
mdrohn - Thursday, July 8, 2004 - link
Heh, I guess that means you are writing from Britain, Pumpkinierre. That special meaning of 'redundancy' in the workplace context of someone losing their job is unknown here in the USA. In fact I'd never heard it in my life until watching 'The Office' on DVD last month ;) We call that layoffs or downsizing here.The electronics/systems meaning I posted was also taken straight from a dictionary.
Pumpkinierre - Thursday, July 8, 2004 - link
Your job becomes redundant when you are no longer of use. You then get a redundancy payout based on the years worked etc.. So I think they initially used the term to describe drives that were no longer of use as they had been replaced by newer bigger drives. My dictionary has redundant as meaning superfluous which is more like your definition, #100, and I suppose you could regard a backup drive as such....until your main drive lets go. So, I dont like the usage of redundancy for duplexed or mirrored drives.mdrohn - Wednesday, July 7, 2004 - link
"Redundancy means of no further use."Actually, 'redundant' more precisely means 'exceeding what is required' or 'exactly duplicating the function or meaning of another', which is an important distinction.
'Redundancy' in an electronics or systems context means 'incorporating extra components that perform the same function in order to cope with failures and errors'. Thus RAID 0 is not, strictly speaking, a 'redundant' array of disks despite its RAID name, since every drive in RAID 0 records different data. RAID 1 is classic redundancy--all the drives in a RAID 1 array are reading and writing exactly the same data.
Pumpkinierre - Wednesday, July 7, 2004 - link
I dont know about that latency increase with RAID. Seek times dont seem to be much affected in reviews I've seen. If the controller reads the drives simultaneously then there shouldnt be much effect on latency.(will it make it to the 6th page?!)
masher - Wednesday, July 7, 2004 - link
> I'm fairly certain that the performance> advantages of having 4 or 5 striped drives are
> likely to be a lot better than just 2...
No, not for ATA drives. You're still limited to the max bandwidth of 133MB/s (150 for some SATA implementations), so beyond 3 drives you don't get the full transfer rate of each drive. Plus, the latency gets worse the more drives you add...with 5 or more drives, your mean latency is essentially your max latency of any single drive.
So a larger array is a repeat of the 2-drive situation. Its much faster in the rare case of a disk-bound app transferring huge files...and no faster (or possibly slightly slower) the rest of the time.
You are right on one thing though. Cheaper (translation: slower) disks would tend to look a bit better here. Not a huge difference, but the slower the disk, the more likely the app is to be disk-bound.
kapowaz - Wednesday, July 7, 2004 - link
Perhaps the review ought to have pointed out what RAID stands for: Redundant Array of *Inexpensive* Disks. The idea is to improve the performance or reliability of a system by using many smaller/cheaper disks compared to using a single expensive disk. Often this isn't the case (I doubt anyone would say the 15krpm disks in modern servers are 'inexpensive'), but the origin behind the technology remains applicable today.Maybe a better test would be to take some cheap disks and see how well they perform. Also, am I not right in thinking that SATA RAID allows for more than just two devices? I'm fairly certain that the performance advantages of having 4 or 5 striped drives are likely to be a lot better than just 2...
masher - Wednesday, July 7, 2004 - link
Umm, MadAd...The "array" of drives can't fail unless a drive in it fails...and it will always fail if one of its drives does. Its just a logical grouping, not a separate entity.Furthermore, MTBF is the wrong statistic to use here. MTTF is the relevant one.
Obviously the raid controller itself could fail, but this is outside the scope of the argument. And such a failure is highly unlikely to impact data in any case.
MadAd - Tuesday, July 6, 2004 - link
"But when we are talking about an ARRAY of drives, the operating life of each individual drive in the array is not what is at issue. What is relevant is ARRAY failure, not DRIVE failure."Are you also trying to say that if the array fails without a drive failing then thats still down to the drives MTBF? wouldnt that be an array MTBF?
If a drive fails in Raid0 then of course we expect the array will fail. If a drive does not fail but the array fails (and you can reuse the drive) then thats nothing to do with the drives MTBF is it? The drives not failed, its still got service life, the array failed. You'll need a different way to measure the chance of an array failure since (unless its connected with a drive failure) its nothing to do with the expected longevity of the components that we measure by drive manufacturers MTBF figures of service life.