The AMD Ryzen Threadripper 1950X and 1920X Review: CPUs on Steroids
by Ian Cutress on August 10, 2017 9:00 AM ESTCPU System Tests
Our first set of tests is our general system tests. These set of tests are meant to emulate more about what people usually do on a system, like opening large files or processing small stacks of data. This is a bit different to our office testing, which uses more industry standard benchmarks, and a few of the benchmarks here are relatively new and different.
All of our benchmark results can also be found in our benchmark engine, Bench.
PDF Opening
First up is a self-penned test using a monstrous PDF we once received in advance of attending an event. While the PDF was only a single page, it had so many high-quality layers embedded it was taking north of 15 seconds to open and to gain control on the mid-range notebook I was using at the time. This put it as a great candidate for our 'let's open an obnoxious PDF' test. Here we use Adobe Reader DC, and disable all the update functionality within. The benchmark sets the screen to 1080p, opens the PDF to in fit-to-screen mode, and measures the time from sending the command to open the PDF until it is fully displayed and the user can take control of the software again. The test is repeated ten times, and the average time taken. Results are in milliseconds.

This opening test is single threaded, so the high-frequency Intel parts get a clear win. There's not much between the Threadripper CPUs here.
FCAT Processing: link
One of the more interesting workloads that has crossed our desks in recent quarters is FCAT - the tool we use to measure and visually analyze stuttering in gaming due to dropped or runt frames. The FCAT process requires enabling a color-based overlay onto a game, recording the gameplay, and then parsing the video file through the analysis software. The software is mostly single-threaded, however because the video is basically in a raw format, the file size is large and requires moving a lot of data around. For our test, we take a 90-second clip of the Rise of the Tomb Raider benchmark running on a GTX 980 Ti at 1440p, which comes in around 21 GB, and measure the time it takes to process through the visual analysis tool.

Similar to PDF opening, single threaded performance wins out.
Dolphin Benchmark: link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in minutes, where the Wii itself scores 17.53 minutes.

Dolphin likes single thread performance as well, although having some cores to back it up seems to be required.
3D Movement Algorithm Test v2.1: link
This is the latest version of the self-penned 3DPM benchmark. The goal of 3DPM is to simulate semi-optimized scientific algorithms taken directly from my doctorate thesis. Version 2.1 improves over 2.0 by passing the main particle structs by reference rather than by value, and decreasing the amount of double->float->double recasts the compiler was adding in. It affords a ~25% speed-up over v2.0, which means new data.
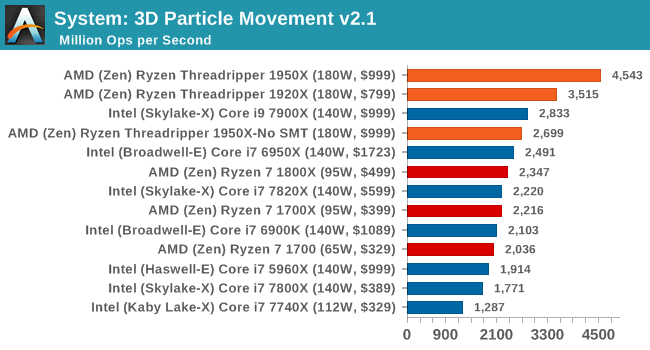
Our first pure multithreaded test, and the 1950X wins with 32 threads. The 1920X beats the 1950X in SMT-off mode, due to 24 threads beating 16 threads.
DigiCortex v1.20: link
Despite being a couple of years old, the DigiCortex software is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation. The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
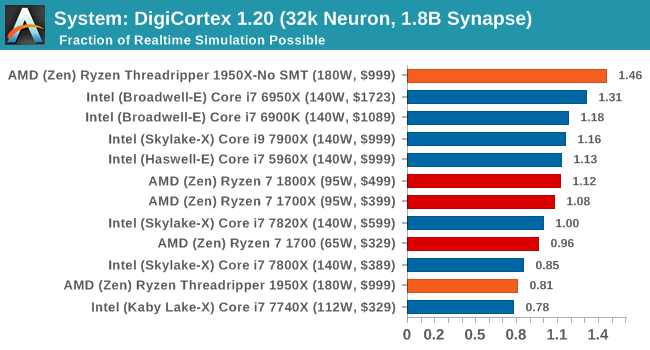
DigiCortex requires a mash of CPU frequency and DRAM performance to get a good result, and anything with quad-channel memory is usually preferred. The 1950X in SMT-off mode wins here due to its low main memory latency combined with having 16 threads to access it. The Broadwell-E is the nearest competitor, over Skylake-X, most likely due to the mesh vs ring topology. The 1950X in Creator mode scores way down the field however, lower than the standard Ryzen chips, showing that under a unified memory architecture there can be significant performance drops. The 1920X failed in this test for an unknown reason.
Agisoft Photoscan 1.0: link
Photoscan stays in our benchmark suite from the previous version, however now we are running on Windows 10 so features such as Speed Shift on the latest processors come into play. The concept of Photoscan is translating many 2D images into a 3D model - so the more detailed the images, and the more you have, the better the model. The algorithm has four stages, some single threaded and some multi-threaded, along with some cache/memory dependency in there as well. For some of the more variable threaded workload, features such as Speed Shift and XFR will be able to take advantage of CPU stalls or downtime, giving sizeable speedups on newer microarchitectures.
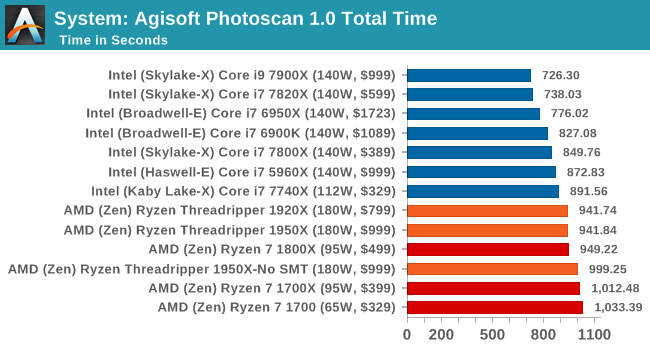
The variable threaded nature of Agisoft shows that in our workflow, it's a mix of cores, IPC and frequency required to win. AMD takes a back seat here, likely due to its AVX implementation.








347 Comments
View All Comments
verl - Thursday, August 10, 2017 - link
"well above the Ryzen CPUs, and batching the 10C/8C parts from Broadwell-E and Haswell-E respectively"??? From the Power Consumption page.
bongey - Thursday, August 10, 2017 - link
Yep if you use AVX-512 it will down clock to 1.8Ghz and draw 400w just for the CPU alone and 600w from the wall. See der8auer's video title "The X299 VRM Disaster (en)", all x299 motherboards VRMs can be ran into thermal shutdown under avx 512 loads, with just a small overclock, not to mention avx512 crazy power consumption. That is why AMD didn't put avx 512 in Zen, it is power consumption monster.TidalWaveOne - Thursday, August 10, 2017 - link
Glad I went with the 7820X for software development (compiling).raddude9 - Thursday, August 10, 2017 - link
In ars' review they have TR-1950X ahead of the i9-7900X for compilation:https://arstechnica.co.uk/gadgets/2017/08/amd-thre...
In short it's very difficult to test compilation, every project you build has different properties.
emn13 - Thursday, August 10, 2017 - link
Yeah, the discrepency is huge - converted to anandtech's compile's per day the arstechnica benchmark maxes out at a little less than 20, which is a far cry from the we see here.Clearly, the details of the compiler, settings and codebase (and perhaps other things!) matter hugely.
That's unfortunate, because compilation is annoyingly slow, and it would be a boon to know what to buy to ameliorate that.
prisonerX - Thursday, August 10, 2017 - link
This is very compiler dependent. My compiler is blazingly fast on my wimpy hardware becuase it's blazingly clever. Most compilers seem to crawl no matter what they run on.bongey - Thursday, August 10, 2017 - link
Looks like anandtech's benchmark for compiling is bunk, it's just way off from all the other benchmarks out there. Not only that, no other test shows a 20% improvement over the 6950x which is also a 10 core/20 thread cpu. Something tells me the 7900x is completely wrong or has something faster like a different pcie ssd.Chad - Thursday, August 10, 2017 - link
All I know is, for those of us running Plex, SABnzbd, Sonarr, Radarr servers simultaneously (and others), while encoding and gaming all simultaneously, our day has arrived!:)
Ian Cutress - Thursday, August 10, 2017 - link
We checked with Ars as to their method.We use a fixed late March build around v56 under MSVC
Ars use a fixed newer build around v62 via clang-cl using VC++ linking
Same software, different compilers, different methods. Our results are faster than Ars, although Ars' results seem to scale better.
ddriver - Friday, August 11, 2017 - link
Of every review out there, only your "superior testing methodology" presents a picture where TR is slower than SX.