AMD's Future in Servers: New 7000-Series CPUs Launched and EPYC Analysis
by Ian Cutress on June 20, 2017 4:00 PM EST- Posted in
- CPUs
- AMD
- Enterprise CPUs
- EPYC
- Whitehaven
- 1P
- 2P
Power
As with the Ryzen parts, EPYC will support 0.25x multipliers for P-state jumps of 25 MHz. With sufficient cooling, different workloads will be able to move between the base frequency and the maximum boost frequency in these jumps – AMD states that by offering smaller jumps it allows for smoother transitions rather than locking PLLs to move straight up and down, providing a more predictable performance implementation. This links into AMD’s new strategy of performance determinism vs power determinism.
Each of the EPYC CPUs include two new modes, one based on power and one based on performance. When a system configured at boot time to a specific maximum power, performance may vary based on the environment but the power is ultimately limited at the high end. For performance, the frequency is guaranteed, but not the power. This enables AMD customers to plan in advance without worrying about how different processors perform with regards voltage/frequency/leakage, or helps provide deterministic performance in all environments. This is done at the system level at boot time, so all VMs/containers on a system will be affected by this.
This extends into selectable power limits. For EPYC, AMD is offering the ability to run processors at a lower or higher TDP than out of the box – most users are likely familiar with Intel’s cTDP Up and cTDP Down modes on the mobile processors, and this feature by AMD is somewhat similar. As a result, the TDP limits given at the start of this piece can go down 15W or up 20W:
| EPYC TDP Modes | ||
| Low TDP | Regular TDP | High TDP |
| 155W | 180W | 200W |
| 140W | 155W | 175W |
| 105W | 120W | - |
The sole 120W processor at this point is the 8-core EPYC 7251 which is geared towards memory limited workloads that pay licenses per core, hence why it does not get a higher power band to work towards.
Workload-Aware Power Management
One of AMD’s points about the sort of workloads that might be run on EPYC is that sporadic tasks are sometimes hard to judge, or are not latency sensitive. In a non-latency sensitive environment, in order to conserve power, the CPU could spread the workload out across more cores at a lower frequency. We’ve seen this sort of policy before on Intel’s Skylake and up processors, going so far as duty cycling at the efficiency point to conserve power, or in the mobile space. AMD is bringing this to the EPYC line as well.

Rather than staying at the high frequency and continually powering up and down, by reducing the frequency such the cores are active longer, latency is traded for power efficiency. AMD is claiming up to a 10% perf-per-Watt improvement with this feature.
Frequency and voltage can be adjusted for each core independently, helping drive this feature. The silicon implements per-core linear regulators that work with the onboard sensor control to adjust the AVFS for the workload and the environment. We are told that this helps reduce the variability from core-to-core and chip-to-chip, with regulation supported with 2mV accuracy. We’ve seen some of this in Carrizo and Bristol Ridge already, although we are told that the goal for per-core VDO was always meant to be EPYC.
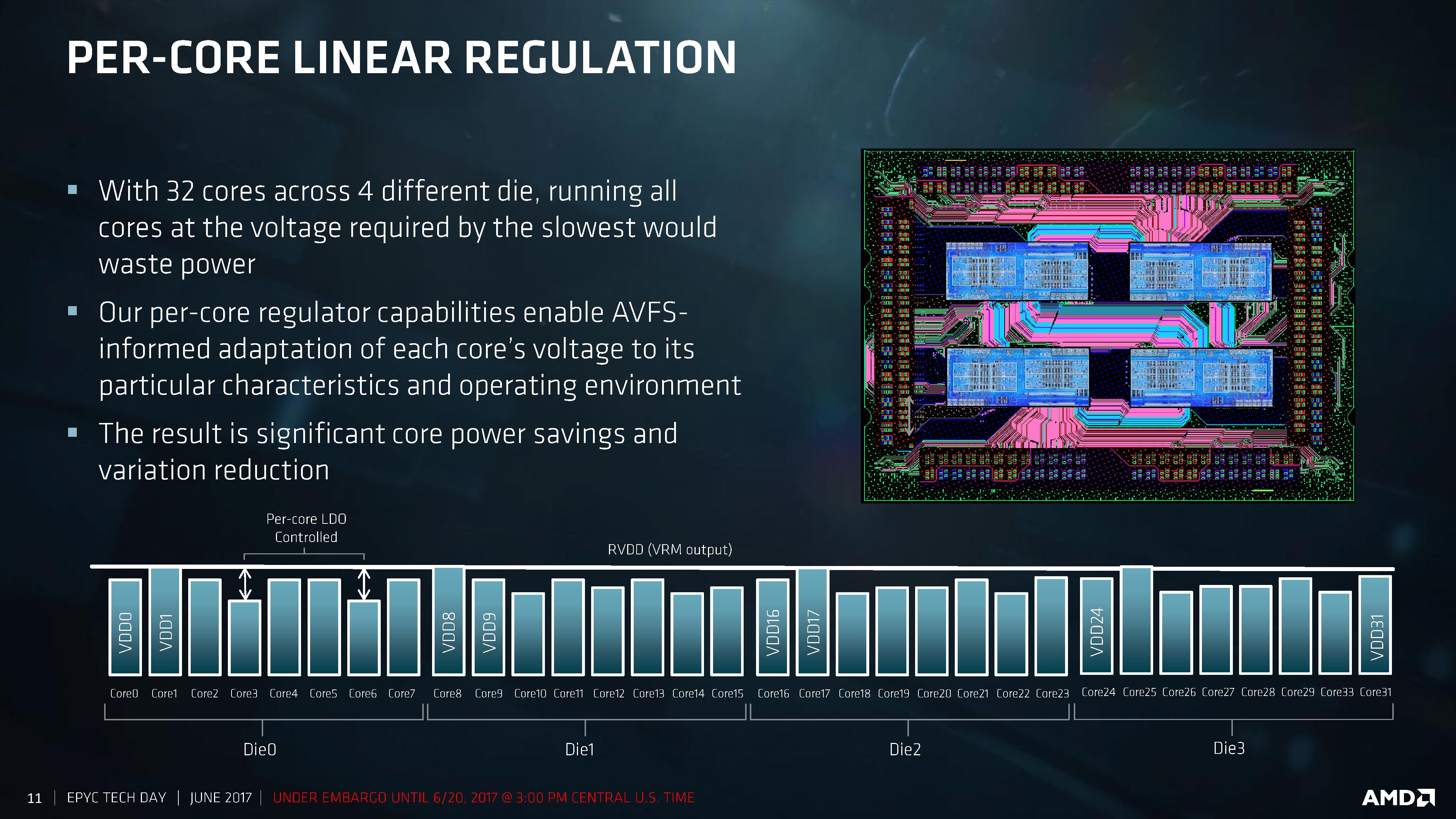
This can not only happen on the core, but also on the Infinity Fabric links between the CPU dies or between the sockets. By modulating the link width and analyzing traffic patterns, AMD claims another 8% perf-per-Watt for socket-to-socket communications.
Performance-Per-Watt Claims
For the EPYC system, AMD is claiming power efficiency results in terms of SPEC, compiled on GCC 6.2:
| AMD Claims 2P EPYC 7601 vs 2P E5-2699A V4 |
||
| SPECint | SPECfp | |
| Performance | 1.47x | 1.75x |
| Average Power | 0.96x | 0.99x |
| Total System Level Energy | 0.88x | 0.78x |
| Overall Perf/Watt | 1.54x | 1.76x |
Comparing a 2P high-end EPYC 7601 server against Intel’s current best 2P E5-2699A v4 arrangement, AMD is claiming a 1.54x perf/watt for integer performance and 1.76x perf/watt on floating point performance, giving more performance for a lower average power resulting in overall power gains. Again, we cannot confirm these numbers, so we look forward to testing.








131 Comments
View All Comments
Gothmoth - Tuesday, June 20, 2017 - link
i read AMD reduced the benchmark numbers for intel by 46% because of compiler benefits for intel...can someone look at the fineprint and confirm or rebunk this???
spikebike - Tuesday, June 20, 2017 - link
Well AMD is comparing a benchmark compiled with gcc-6.2 and running on Intel vs the same benchmark comiled with gcc-6.2 and running on AMD. For people who compile their own binaries with gcc this is quite fair. However intel's compiler is sometimes substantially faster than gcc, question is are the binaries you care about (Games? Handbrake? Something else?) compiled with intel's compiler or gcc?Gothmoth - Tuesday, June 20, 2017 - link
you could be right but it reads on tomshardware as if they just take the numbers provided by intel and reduce them.. they actually don´t test on intel. the just take numbers from intel and reduce them by 46%.hamoboy - Tuesday, June 20, 2017 - link
From what I read they tested the flagship Xeon, found the performance multiplier (~0.57), then extrapolated them across the rest of the range. So not completely scummy, but still cause to wait for actual benchmarks.TC2 - Wednesday, June 21, 2017 - link
according to the numbersE5-2698 v4 / EPYC 7551 ~~ 1.11
all this looks quite misleading! but this is amd :)
TC2 - Wednesday, June 21, 2017 - link
1.11 per core i mean to sayRyan Smith - Tuesday, June 20, 2017 - link
We still need to independently confirm the multiplier, but yes, AMD is reducing Intel's official SPEC scores."Scores for these E5 processors extrapolated from test results published at www.spec.org, applying a conversion multiplier to each published score"
davegraham - Tuesday, June 20, 2017 - link
Jeff @ Techreport has the multiplier officially listed.deltaFx2 - Wednesday, June 21, 2017 - link
Intel "cheats" in the icc compiler when compiling SPEC workloads. Libquantum is most notorious for such cheating but many others are also prone to this issue. In Libq, the icc compiler basically reorganize the datastructures and memory layout to get excellent vectorization, and I think 1/10th the bandwidth requirements as compared to gcc -O2. These transformations are there only for libquantum so it has little to no use for general workloads. Hence gcc (and llvm) reject such transformations. It's not unlike VW's emission defeat devices, actually.Go to Ars Technica. They have the full dump of slides. AMD does benchmark Xeon 1 or 2 systems themselves. However for some of the graphs where Xeon data is presented, they use Intel's published numbers (on icc of course), and derate it by this factor to account for this cheating. You could argue that AMD should have benched all the systems themselves and that's fair enough. But I don't think Tom's hardware is exactly qualified to know or state that the derate is 20% and not 40% or whatever. They benchmark consumer hardware, and wouldn't know a thing about this. So any number coming from these sources are dubious.
patrickjp93 - Wednesday, June 21, 2017 - link
Wrong. See the CPPCon 2015/2016 "Compiler Switches" talks. ICC does not CHEAT at all. It hasn't since 2014.Intel wins purely on merit.