AMD's Future in Servers: New 7000-Series CPUs Launched and EPYC Analysis
by Ian Cutress on June 20, 2017 4:00 PM EST- Posted in
- CPUs
- AMD
- Enterprise CPUs
- EPYC
- Whitehaven
- 1P
- 2P
With recent fears about security, and given that these processors are aiming to go to the Enterprise space, AMD had to dedicate some time to explaining how secure the new platform is. AMD has had its Secure Processor in several CPUs at this point: a 32-bit ARM Cortex-A5 acting as a microcontroller that runs a secure OS/kernel with secure off-chip storage for firmware and data – this helps provide cryptographic functionality for secure key generation and key management. This starts with hardware validated boot (TPM), but includes Secure Memory Encryption and Secure Encrypted Virtualization.
Encryption starts at the DRAM level, with an AES-128 engine directly attached to the MMU. This is designed to protect against physical memory attacks, with each VM and Hypervisor able to generate a separate key for their environment. The OS or Hypervisor can choose which pages to encrypt via page tables, and the DMA engines can provide support for external devices such as network storage and graphics cards to access encrypted pages.
Because each VM or container can obtain its own encryption key, this isolates them from each other, protecting against cross-contamination. It also allows unencrypted VMs to run alongside encrypted ones, removing the all-or-nothing scenario. The keys are transparent to the VMs themselves, managed by the protected hypervisor. It all integrates with existing AMD-V technology.
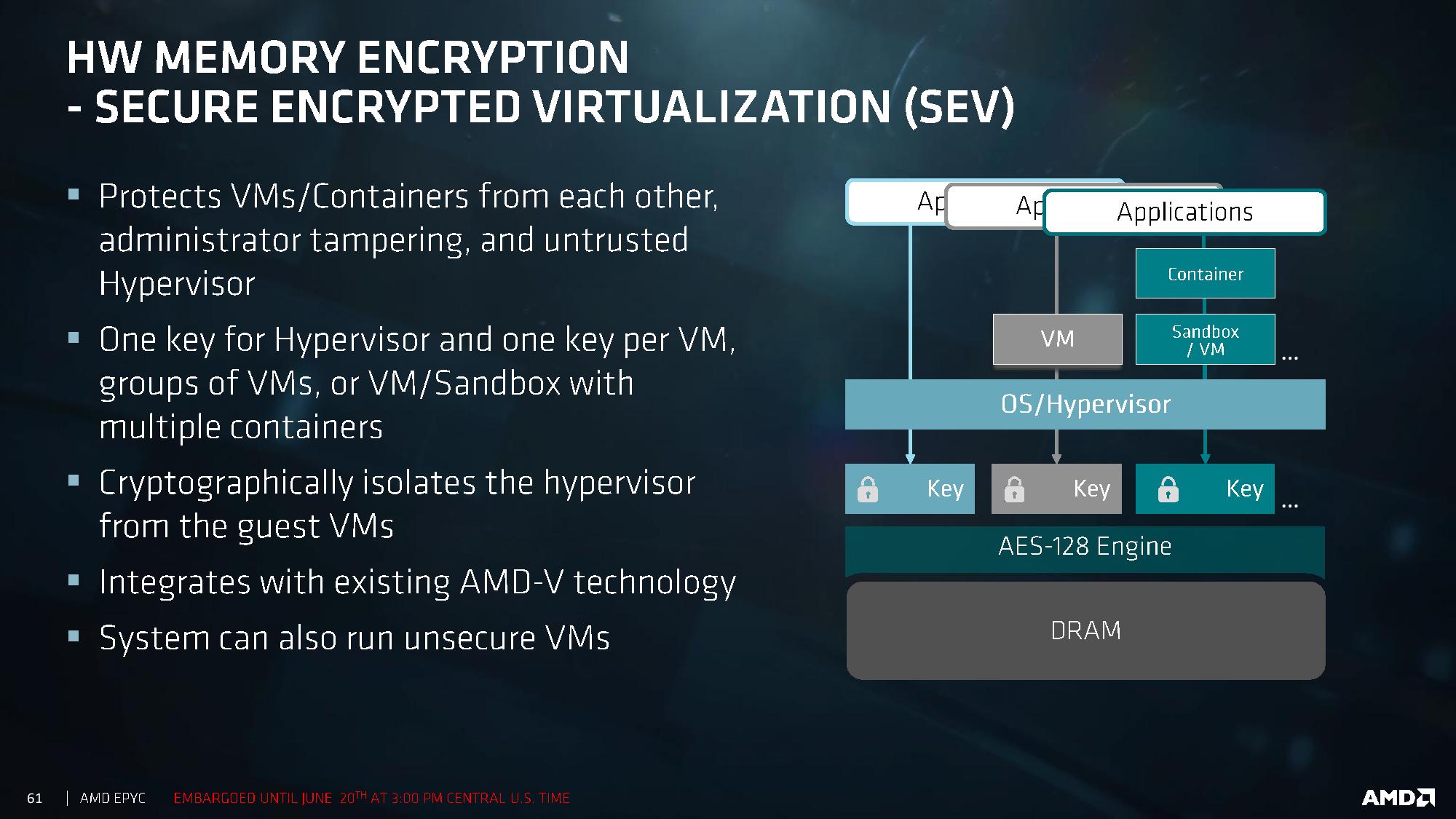
Alongside this are direct RAS features in the core, with the L1 data cache using SEC-DED ECC and L2/L3 caches using DEC-TED ECC. The DRAM support involves x4 DRAM device failure correction with addr/cmd parity and write CRC with replay. Data poisoning is handled with reporting and a machine check recovery mode. The Infinity Fabric between dies and between sockets is also link-packet CRC backed with retry.
One element that was not discussed is live VM migration across encrypted environments. We fully suspect that an AMD-to-AMD live migration be feasible, although an AMD-to-Intel or Intel-to-AMD will have issues, given that each microarchitecture has unique implementations of certain commands.








131 Comments
View All Comments
msroadkill612 - Wednesday, June 21, 2017 - link
Sounds a powerful feature for vid editors etc."Hot-swap NVMe/SAS3/SATA3
drive bays and M.2 slots"
Breit - Wednesday, June 21, 2017 - link
Really?: http://images.anandtech.com/galleries/5699/epyc_te..."All 2P E5 scores were derived from the following ICC compiler-based test results per spec.org, multiplied by 0.575 to convert them from the ICC compiler to GCC -O2 v6.1..."?!?
Not cool.
TC2 - Wednesday, June 21, 2017 - link
i smell a tragedy for amd with those "multiplications" :)HollyDOL - Wednesday, June 21, 2017 - link
Reminds me so called "Resultin's constant" joke...[Value you get] [any operator] [Resultin's constant] = [Value you wanted]
TC2 - Wednesday, June 21, 2017 - link
precisely!try another behavioural pattern: great claims, feeble results :)
to compare E5-2698 v4 20 cores with EPYC 7551 32 cores - 32/20 = 1.6, the extrapolation is claimed to be +44% or 1.44.
therefore 1.6/1.44=1.1(1).
now we can to conclude that for a 32 core xeon (it's easy for intel) the result will be +11% for intel, and no more advantage for amd at all!!!
such mathematical practices are ridiculous!
FreckledTrout - Wednesday, June 21, 2017 - link
Anyone buying these is going to want to see some large independent reviews / studies. Some of the larger companies looking at these say like Amazon's data center may get a few and do a study. I think that type of info is what everyone should wait on. These numbers look like they came from the marketing side of the house.Intel999 - Wednesday, June 21, 2017 - link
"Anyone buying these is going to want to see some large independent reviews / studies. Some of the larger companies looking at these say like Amazon's data center may get a few and do a study."Those companies that shared the stage with AMD for this presentation were included in the 5,000 Epyc chips that were given to OEMs/ODMs to test and validate over the last six months.
All the big boys know what EPYC is capable of and it seems that most are quite impressed.
Zizy - Wednesday, June 21, 2017 - link
Yeah well the story is that they obtained GCC 6.1 scores (by benching the CPU) for the top CPU and found out those are ~40% lower than the official ones. Some of that is ICC cheating on tests, some of that is optimization level.So, they reduced all official scores by the same ~40% for this comparison (with the top part being actually benched and achieved that result as on slides).
I can't fault them for using the middle ground GCC for those benchmarks, and the normalization step is reasonable enough as well. The only real issue here is use of -O2 instead of more optimized code. Sure, Ryzen/Epyc is new and GCC likely cannot optimize as good for it (which is probably they reason they used default O2), but this is not a valid excuse, should have used O3 at least if not advanced flags.
petteyg359 - Thursday, June 22, 2017 - link
Don't be a ricer. -O3 is often else than -O2 and EVERYBODY with a clue recommend against using it anywhere, ever.Zan Lynx - Monday, June 26, 2017 - link
Erm. I use GCC with -O3 in a library I build at my job. With profile feedback it is easily 20% faster than -O2. So I don't know where these "clue" people are. I've only been coding for 20 years or so. I may not have a clue yet.