Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Intel's New On-Chip Topology: A Mesh
Since the introduction of the "Nehalem" CPU architecture – and the Xeon 5500 that started almost a decade-long reign for Intel in the datacenter – Intel's engineers have relied upon a low latency, high bandwidth ring to connect their cores with their caches, memory controllers, and I/O controllers.
Intel's most recent adjustment to their ring topology came with the Ivy Bridge-EP (Xeon E5 2600 v2) family of CPUs. The top models were the first with three columns of cores connected by a dual ring bus, which utilized both outer and inner rings. The rings moved data in opposite directions (clockwise/counter-clockwise) in order to minimize latency by allowing data to take the shortest path to the destination. As data is brought onto the ring infrastructure, it must be scheduled so that it does not collide with previous data.
The ring topology had a lot of advantages. It ran very fast, up to 3 GHz. As result, the L3-cache latency was pretty low: if the core is lucky enough to find the data in its own cache slice, only one extra cycle is needed (on top of the normal L1-L2-L3 latency). Getting a cacheline of another slice can cost up to 12 cycles, with an average cost of 6 cycles.
However the ring model started show its limits on the high core count versions of the Xeon E5 v3, which had no less than four columns of cores and LLC slices, making scheduling very complicated: Intel had to segregate the dual ring buses and integrate buffered switches. Keeping cache coherency performant also became more and more complex: some applications gained quite a bit of performance by choosing the right snoop filter mode (or alternatively, lost a lot of performance if they didn't pick the right mode). For example, our OpenFOAM benchmark performance improved by almost 20% by choosing "Home Snoop" mode, while many easy to scale, compute-intensive applications preferred "Cluster On Die" snooping mode.
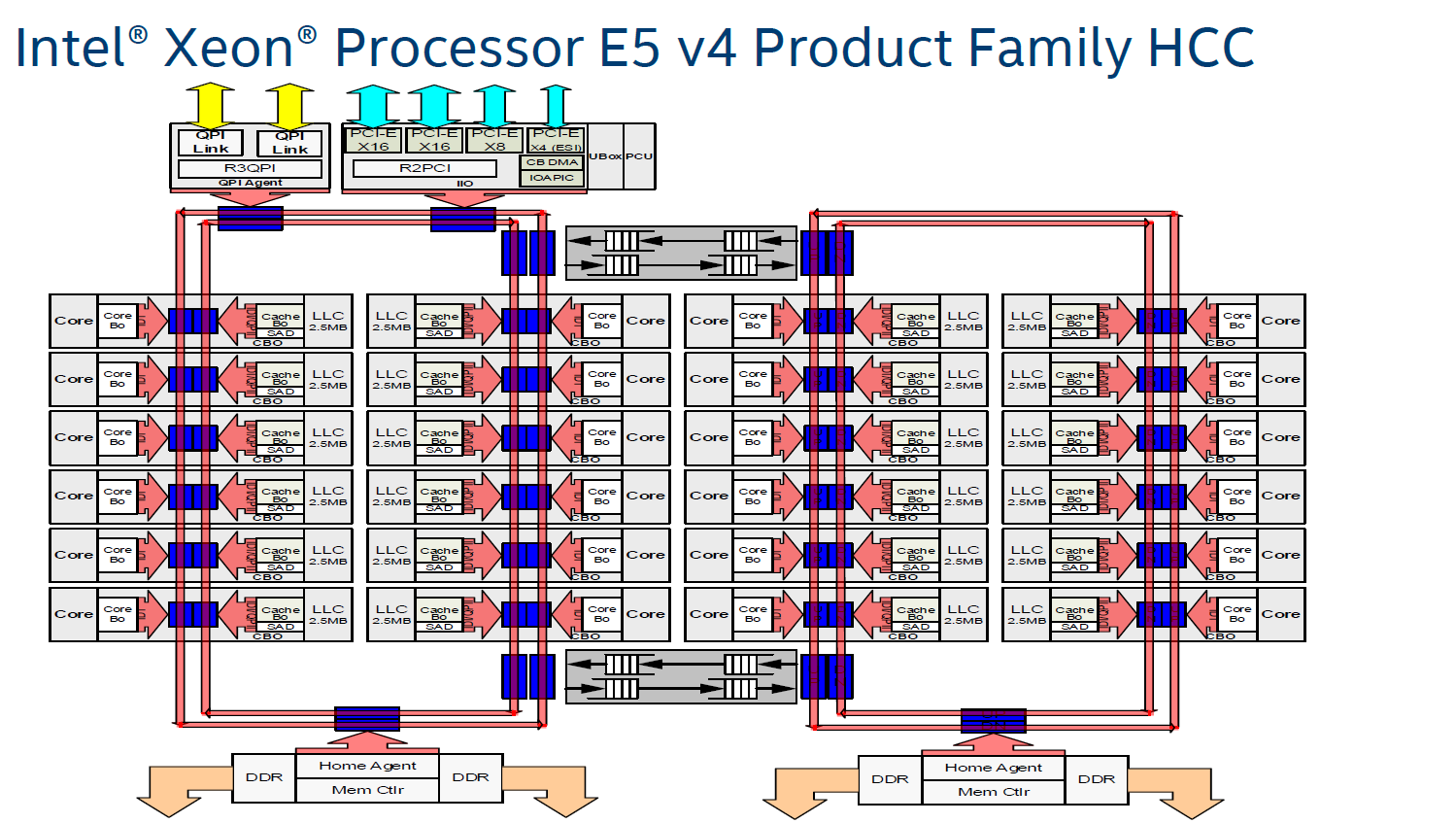
In other words, placing 22 (E7:24) cores, several PCIe controllers, and several memory controllers was close to the limit what a dual ring could support. In order to support an even larger number of cores than the Xeon v4 family, Intel would have to add a third ring, and ultimately connecting 3 rings with 6 columns of cores each would be overly complex.
Given that, it shouldn't come as a surprise that Intel's engineers decided to use a different topology for Skylake-SP to connect up to 28 cores with the "uncore." Intel's new solution? A mesh architecture.
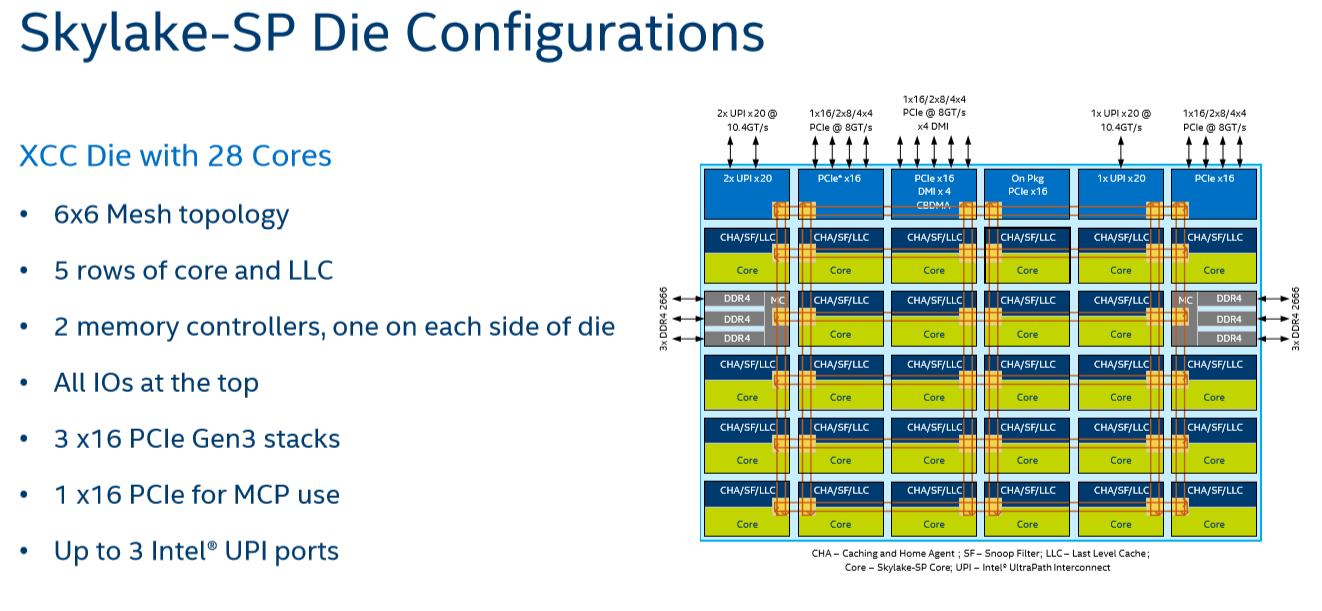
Under Intel's new topology, each node – a caching/home agent, a core, and a chunk of LLC – is interconnected via a mesh. Conceptually it is very similar to the mesh found on Xeon Phi, but not quite the same. In the long-run the mesh is far more scalable than Intel's previous ring topology, allowing Intel to connect many more nodes in the future.
How does it compare to the ring architecture? The Ring could run at up to 3 GHz, while the current mesh and L3-cache runs at at between 1.8GHZ and 2.4GHz. On top of that, the mesh inside the top Skylake-SP SKUs has to support more cores, which further increases the latency. Still, according to Intel the average latency to the L3-cache is only 10% higher, and the power usage is lower.

A core that access an L3-cache slice that is very close (like the ones vertically above each other) gets an additional latency of 1 cycle per hop. An access to a cache slice that is vertically 2 hops away needs 2 cycles, and one that is 2 hops away horizontally needs 3 cycles. A core from the bottom that needs to access a cache slice at the top needs only 4 cycles. Horizontally, you get a latency of 9 cycles at the most. So despite the fact that this Mesh connects 6 extra cores verse Broadwell-EP, it delivers an average latency in the same ballpark (even slightly better) as the former's dual ring architecture with 22 cores (6 cycles average).
Meanwhile the worst case scenario – getting data from the right top node to the bottom left node – should demand around 13 cycles. And before you get too concerned with that number, keep in mind that it compares very favorably with any off die communication that has to happen between different dies in (AMD's) Multi Chip Module (MCM), with the Skylake-SP's latency being around one-tenth of EPYC's. It is crystal clear that there will be some situations where Intel's server chip scales better than AMD's solution.
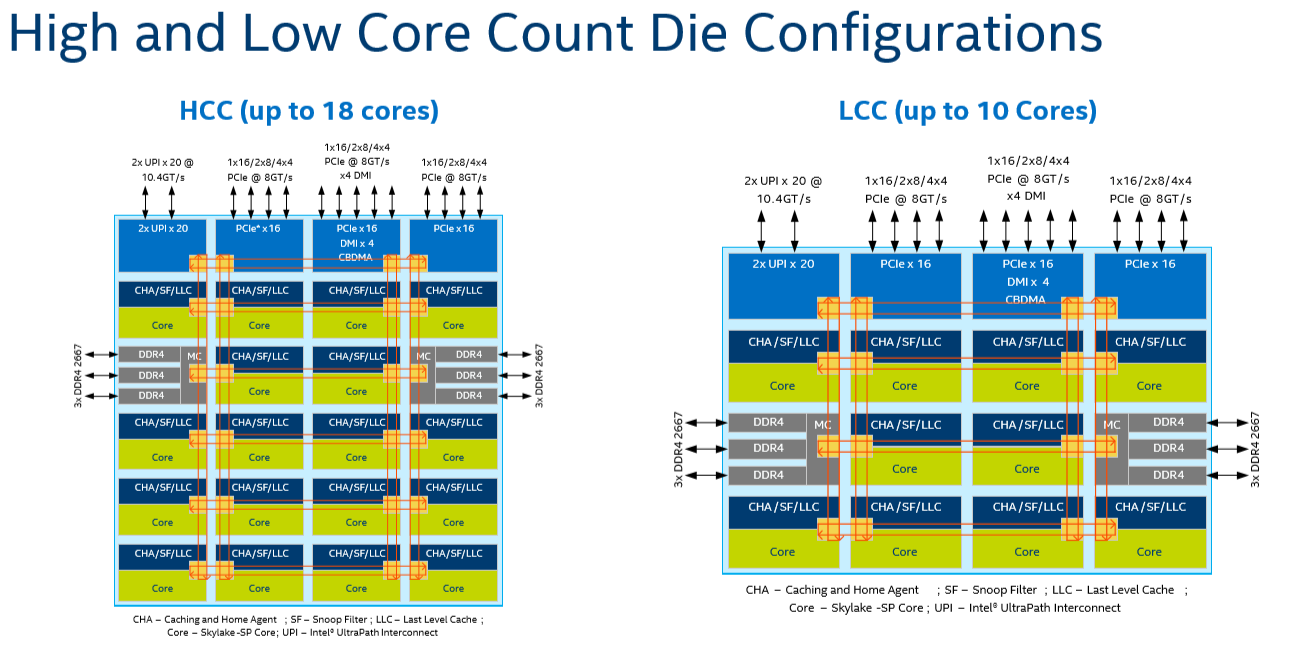
There are other advantages that help Intel's mesh scale: for example, caching and home agents are now distributed, with each core getting one. This reduces snoop traffic and reduces snoop latency. Also, the number of snoop modes is reduced: no longer do you need to choose between home snoop or early snoop. A "cluster-on-die" mode is still supported: it is now called sub-NUMA Cluster or SNC. With SNC you can divide the huge Intel server chips into two NUMA domains to lower the latency of the LLC (but potentially reduce the hitrate) and limit the snoop broadcasts to one SNC domain.








219 Comments
View All Comments
twtech - Thursday, July 20, 2017 - link
I'd really like to see some compile-time benchmarks for these CPUs.For my own particular interests, time taken to do a full recompile of the Unreal 4 engine from source would be very useful. But even something more generic like the Linux kernel compiles per hour benchmark could serve as a useful point of reference.
szupek - Friday, July 21, 2017 - link
Meanwhile, the entire world still runs on IBM's DB2 for Datbases and IBM's Z/AS400 Mainframes. The fastest database in the world, by far...oh and the most secure (it's only hackable by standing in front of the console, seriously). Every single credit card transaction. Every single plain ticket. Most medical records and all of wall street. Yup. IBM still owns. So much that most of commenters probably have no idea just how big IBM truly is. If you care about Database speed & security, these processors shouldn't appeal to you.stevefan1999 - Saturday, July 22, 2017 - link
It's impossible for AMD to win completely.Remember kids, public cloud service providers such as Amazon(AWS), Google(GCP) and Joyent would still stick with Intel due to not only the compatibility issues like ecosystem and vendor inconsistency, but also the VM migration and security and module issues, all mentioned in the presentation slides presented by Intel. They are a very serious matter, as they, the public cloud services, are powering the Internet we use everyday, so being stable, consistent and be able to serve a good amount of SLA is vital to the public cloud, we wouldn't expect them to play with the new lad in the hood, the EPYC.
IIRC only the Microsoft(Azure) are using AMD server CPUs partially in some of their datacenters, running various Linux and Windows VMs using Hyper-V, and they have been performing quite well
The cloud services are exploding every year, but with what I've said, I doubt AMD could even kick in the first door at least for 3 to 4 years. This is still a big-win for Intel and what manipulations will Intel do I don't know.
On the other hand, Intel has failed to service the desktop market and they're figuring out how to hold their asses on the Internet infrastructure, never had them know the crusade of EPYC will come this fast.
The server market is quite a big meat, it's a 21 bil market, cool right? But that you will have guaranteed 'server upgrade' every year, is a bigger matter, as those server CPUs are designated to be disposed given the wattage and performance per dollar is lower on the newer CPUs. Those god-damn server operators will keen to replace their CPU (and therefore some serious metal pollution issues). Intel has been exploiting this and gained a big hurdle of money and therefore had their ecosystem grown. This is how Intel defends their platform by vendor lock-in, pathetic.
AMD is now being performance and cost competitive to Intel, but it's still dead in the High Performance Computing campaign unless AMD could provide higher frequencies. Well I have to say I know nothing about HPC, but I remembered the Bulldozer architecture of AMD is actually targeted and marketed for HPC! That's why AMD failed in general-purpose computing market and started the downfall of AMD/Domination of Intel 5 years ago. Even though we know the fate of Bulldozer, but hopefully AMD could still scrap some of the HPC goodies of Bulldozer out and benefits the mankind by accelerating researches such as finding the cures for cancer or solving some precise physics and mathematics.
Well, anyway the cloud, the HPC and the server market are the last resort for Intel and they will definitely hold their last ground. Good luck AMD on crushing the mean and obese Intel!
errorr - Sunday, July 23, 2017 - link
For all the talk about speed and efficiency the problem is about $$$. The sad fact is that what matters most isn't even the price of the cpus which is chump change in the grand scheme of things but how the software licensing costs are determined. Per core or per socket software pricing will matter a lot. The software companies will decide how successful EPYC is. I have a feeling they will be biased slightly toward AMD at the beginning as it is in their interest to foster competition for Intel, or if they are not forward looking enough the end customers might argue that the competition will benefit the SW companies in the long run by continuing to push competition.msroadkill612 - Thursday, July 27, 2017 - link
Whatever, its all pointless if the competition can read your secrets, which is a matter very close to the hearts of the cheque signers.AMD seem to have something very superior to offer in that department.
qweqwe - Tuesday, August 8, 2017 - link
we just did some heavy inhouse hpc-tests with epyc against diff. intel servers.the epyc is the clear winner in terms of performance and power consumption when it
comes to hand-tuned parallel-vector-code examples.
not bad amd !
readonly1 - Friday, October 27, 2017 - link
qweqwe, I totally agree with you. Our inhouse HPC tests get the similar conclusion, after comparing AMD Epyc 7351 (dual socket, 32 cores, 2400Mhz) and Intel SKylake 6154 (dual socket, 36 cores, 3000Mhz). I think AMD clearly wins in the memory bandwidth, which is extremely important for HPC computation.msroadkill612 - Monday, November 13, 2017 - link
7/11/2017 "Microsoft is already deploying AMD's EPYC in their Azure Cloud Datacenters."Interesting. As i have been theorising, a possible reason for the absence of retail epyc is not supply, but demand.
A single sale can soak up production runs.
If so tho, not much sign of big revenues from it yet, but there are other explanations for that. Contra processors for development work e.g.
q.epsilon.p - Sunday, June 10, 2018 - link
power consumption numbers with every benchmark would have been nice, because these parts are server benchmarks, Perf / Watt is one of the primary concerns. And where AMD kinda crush Intel, because it's isn't exactly being honest with it's TDP values nowadays when it comes to Data Centre and HEDT.TDP was traditionally the absolute maximum the CPU would put out as heat, now with a power consumption of 670W I am assuming that the heat being put out by the CPU is more than 165W.