HiSilicon Kirin 960: A Closer Look at Performance and Power
by Matt Humrick on March 14, 2017 7:00 AM EST- Posted in
- Smartphones
- Mobile
- SoCs
- HiSilicon
- Cortex A73
- Kirin 960
CPU Performance
We’ll begin our Kirin 960 performance evaluation by investigating the A73’s integer and floating-point IPC with some synthetic tests. Then we’ll see how the changes to its memory system affect memory latency and bandwidth. Finally, after completing the lower-level tests, we’ll see how Huawei’s Mate 9 and its Kirin 960 SoC perform when running some real-world workloads.
Our first look at the A73’s integer performance comes from SPECint2000, the integer component of the SPEC CPU2000 benchmark developed by the Standard Performance Evaluation Corporation. This collection of single-threaded tests allows us to compare IPC for competing CPU microarchitectures. The scores below are not officially validated numbers, which requires the test to be supervised by SPEC, but we’ve done our best to choose appropriate compiler flags and to get the tests to pass internal validation.
| SPECint2000 - Estimated Scores ARMv8 / AArch64 |
||||
| Kirin 960 | Kirin 950 (% Advantage) |
Exynos 7420 (% Advantage) |
Snapdragon 821 (% Advantage) |
|
| 164.zip | 1217 | 1094 (11.3%) |
940 (29.5%) |
1273 (-4.4%) |
| 175.vpr | 4118 | 3889 (5.9%) |
2857 (44.1%) |
1687 (144.1%) |
| 176.gcc | 2157 | 1864 (15.7%) |
1294 (66.7%) |
1746 (23.5%) |
| 181.mcf | 1118 | 664 (68.3%) |
928 (20.5%) |
1200 (-6.8%) |
| 186.crafty | 2222 | 2083 (6.7%) |
1176 (88.9%) |
1613 (37.8%) |
| 197.parser | 1395 | 1208 (15.5%) |
933 (49.5%) |
1059 (31.8%) |
| 252.eon | 3421 | 3333 (2.6%) |
2453 (39.5%) |
3714 (-7.9%) |
| 253.perlmk | 1748 | 1651 (5.8%) |
1216 (43.8%) |
1513 (15.5%) |
| 254.gap | 1930 | 1667 (15.8%) |
1264 (52.6%) |
1594 (21.1%) |
| 255.vortex | 2111 | 1863 (13.3%) |
1473 (43.3%) |
1712 (23.3%) |
| 256.bzip2 | 1402 | 1220 (15.0%) |
1079 (29.9%) |
1172 (19.6%) |
| 300.twolf | 2479 | 2521 (-1.7%) |
1887 (31.4%) |
847 (192.6%) |
The Kirin 960’s A73 CPU is about 11% faster on average than the Kirin 950’s A72. In addition to the front-end changes discussed on the previous page and the changes to the memory system discussed in the next section, the A73’s integer pipelines have undergone a few tweaks as well. Where the A72 had 3 integer ALUs—2 simple ALUs for basic operations such as addition and shifting and 1 dedicated multi-cycle ALU for complex operations such as multiplication, division, and multiply-accumulate—the A73 only has 2 integer ALUs that are capable of performing both basic and complex operations. This affects performance in different ways. For example, because only one of the A73’s ALUs can handle multiplication while the other handles division, the time to execute multiply or division operations sees no change; however, while an ALU is occupied with a multi-cycle instruction, it cannot execute simple instructions like the A72’s dedicated pipelines can, leading to a potential performance loss. Multiply-accumulate operations, which require both of the A73’s pipelines, incur a similar penalty. It’s not all bad, however. Workloads that perform parallel arithmetic or use certain other complex instructions can see double the execution throughput on A73 versus A72.
Note that the table above does not account for differences in CPU frequency. The Kirin 960’s frequency advantage over the Kirin 950 and Snapdragon 821 is less than 3%, making these numbers easier to compare, but its advantage over the Exynos 7420 is a little over 12%. The chart below accounts for this by dividing the estimated SPECint2000 ratio score by CPU frequency, making IPC comparisons easier.

Despite the substantial microarchitectural differences between the A73 and A72, the A73’s integer IPC is only 11% higher than the A72’s. This is likely the result of improvements in one area being partially offset by regressions in another. Still, assuming ARM’s power reduction claims hold true, this is not a bad result.
The gap between the A73 and A57 increases to 29%. The integer performance for Qualcomm’s custom Kryo core is well behind ARM’s A73 and A72 cores, essentially matching the A57’s IPC.
| Geekbench 4 - Integer Performance Single Threaded |
||||
| Kirin 960 | Kirin 950 (% Advantage) |
Exynos 7420 (% Advantage) |
Snapdragon 821 (% Advantage) |
|
| AES | 911.3 MB/s | 935.6 MB/s (-2.59%) |
795.8 MB/s (14.52%) |
559.1 MB/s (63.00%) |
| LZMA | 3.03 MB/s | 2.87 MB/s (5.69%) |
2.28 MB/s (33.33%) |
2.20 MB/s (38.09%) |
| JPEG | 16.1 Mpixels/s | 15.5 Mpixels/s (3.66%) |
14.1 Mpixels/s (13.95%) |
21.6 Mpixels/s (-25.62%) |
| Canny | 22.5 Mpixels/s | 26.8 Mpixels/s (-16.06%) |
23.6 Mpixels/s (-4.80%) |
30.3 Mpixels/s (-25.77%) |
| Lua | 1.70 MB/s | 1.55 MB/s (10.13%) |
1.20 MB/s (41.94%) |
1.47 MB/s (16.14%) |
| Dijkstra | 1.53 MTE/s | 1.14 MTE/s (33.53%) |
0.92 MTE/s (65.12%) |
1.39 MTE/s (9.57%) |
| SQLite | 51.6 Krows/s | 43.5 Krows/s (18.62%) |
34.0 Krows/s (51.99%) |
36.7 Krows/s (40.73%) |
| HTML5 Parse | 8.30 MB/s | 6.79 MB/s (22.19%) |
6.37 MB/s (30.25%) |
7.61 MB/s (9.02%) |
| HTML5 DOM | 2.17 Melems/s | 1.92 Melems/s (12.82%) |
1.26 Melems/s (72.91%) |
0.37 Melems/s (489.09%) |
| Histogram Equalization | 48.7 Mpixels/s | 57.0 Mpixels/s (-14.56%) |
50.6 Mpixels/s (-3.66%) |
51.2 Mpixels/s (-4.82%) |
| PDF Rendering | 44.8 Mpixels/s | 45.5 Mpixels/s (-1.47%) |
39.7 Mpixels/s (12.93%) |
53.0 Mpixels/s (-15.36%) |
| LLVM | 194.4 functions/s | 167.9 functions/s (15.76%) |
128.6 functions/s (51.14%) |
113.5 functions/s (71.20%) |
| Camera | 5.45 images/s | 5.45 images/s (0.00%) |
4.95 images/s (10.17%) |
7.19 images/s (-24.12%) |
The updated Geekbench 4 workloads give us a second look at integer IPC. Similar to the SPECint2000 results, we see Kirin 960 showing 5% to 15% gains over Kirin 950 in several of the tests, but there’s a bit more variation overall. The Kirin 960 is actually slower than Kirin 950 in some tests, and, in the case of Canny and Histogram Equalization, its A73 is even slower than the Exynos 7420’s A57. It also falls behind Qualcomm’s Kryo in the JPEG, PDF Rendering, and Camera tests. The tests where the Kirin 960 does well—HTML5 Parse, HTML5 DOM, and SQLite—are very common workloads, though, which should translate into better real-world performance.
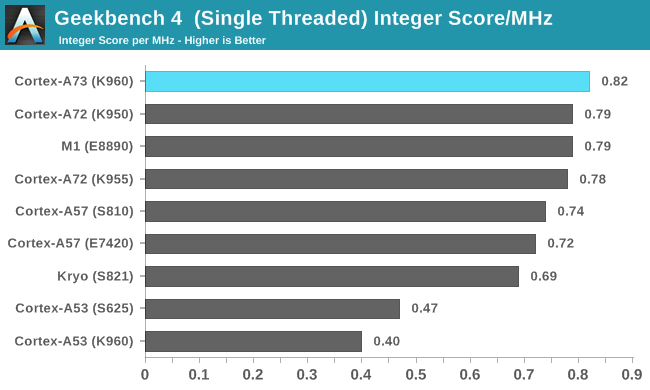
The chart above accounts for differences in CPU frequency, making it easier to directly compare IPC. Overall the A73 shows only about a 4% improvement over the A72 and about a 12% improvement over the A57 in this group of workloads, considerably less than what we saw in SPECint2000; however, with margins ranging from 33.5% in Dijkstra to -16.1% in Canny, it’s impossible to make any sweeping statements about the A73’s integer performance being better or worse than the A72’s.
Qualcomm’s Kryo CPU falls just behind the A57 once again despite posting better results in many of the Geekbench integer tests. Its poor performance in LLVM and HTML5 DOM weighs heavily on its overall score.
I’ve also included results for ARM’s in-order A53 companion core. The A73’s integer IPC is 1.7x to 2x higher overall, which illustrates why octa-core A53 SoCs are so much slower, particularly in Web browsing, than designs that use 2-4 big cores (A73/A72/A57) instead of 4 additional A53s.
| Geekbench 4 - Floating Point Performance Single Threaded |
||||
| Kirin 960 | Kirin 950 (% Advantage) |
Exynos 7420 (% Advantage) |
Snapdragon 821 (% Advantage) |
|
| SGEMM | 10.7 GFLOPS | 13.9 GFLOPS (-23.44%) |
11.9 GFLOPS (-10.36%) |
12.2 GFLOPS (-12.57%) |
| SFFT | 2.89 GFLOPS | 2.26 GFLOPS (27.73%) |
2.62 GFLOPS (10.39%) |
3.21 GFLOPS (-10.07%) |
| N-Body Physics | 838.4 Kpairs/s | 896.9 Kpairs/s (-6.52%) |
634.5 Kpairs/s (32.14%) |
1156.7 Kpairs/s (-27.51%) |
| Rigid Body Physics | 5891.4 FPS | 6497.4 FPS (-9.33%) |
4662.7 FPS (26.35%) |
7171.3 FPS (-17.85%) |
| Ray Tracing | 221.9 Kpixels/s | 216.9 Kpixels/s (2.30%) |
136.1 Kpixels/s (63.07%) |
298.3 Kpixels/s (-25.59%) |
| HDR | 7.46 Mpixels/s | 7.57 Mpixels/s (-1.45%) |
7.17 Mpixels/s (4.09%) |
10.8 Mpixels/s (-30.90%) |
| Gaussian Blur | 23.6 Mpixels/s | 28.6 Mpixels/s (-17.37%) |
24.4 Mpixels/s (-2.94%) |
48.5 Mpixels/s (-51.27%) |
| Speech Recognition | 12.8 Words/s | 8.9 Words/s (44.14%) |
10.2 Words/s (25.49%) |
10.9 Words/s (17.43%) |
| Face Detection | 501.2 Ksubs/s | 518.9 Ksubs/s (-3.42%) |
435.5 Ksubs/s (15.09%) |
685.0 Ksubs/s (-26.83%) |
With the exception of SFFT and Speech Recognition, the Kirin 960 is generally a little slower than the Kirin 950 in Geekbench 4’s floating-point workloads. This is a bit of a surprise considering that the A73’s NEON execution units are relatively unchanged from the A72’s design, with reduced latency for specific instructions improving NEON performance by 5%, according to ARM. These results are even harder to interpret after factoring in the A73’s lower-latency front end and improvements to its fetch block and memory subsystems. It’s possible that some of these tests are limited by the A73’s narrower decode stage, but given the variation in workloads, this is probably not true for every case. It will be interesting to see if A73 implementations from other SoC vendors show similar results.
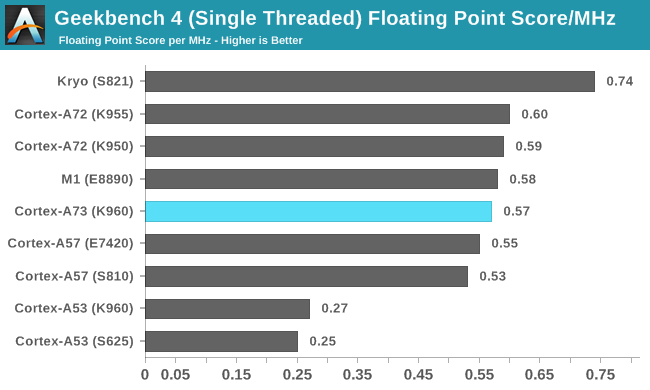
After accounting for the differences in CPU frequency, floating-point IPC for the Kirin 960’s A73 is 3% to 5% lower overall than the A72 but about 3% higher than the older A57. These results, which are a geometric mean of the floating-point subtest scores, are certainly closer to what I would expect, but hide the large performance variation from one workload to the next.
It’s pretty obvious that floating-point performance was Qualcomm’s focus for its custom Kryo core. While integer IPC was no better than ARM’s A57, Kryo’s floating-point IPC is 23% higher than the A72 in Geekbench 4, with particularly strong results in the Gaussian Blur and HDR tests.








86 Comments
View All Comments
BedfordTim - Tuesday, March 14, 2017 - link
I suspect it comes down to cost and usage. The iPhone cores are roughly four times the size of an A73.name99 - Tuesday, March 14, 2017 - link
True. But the iPhone cores are still small ENOUGH. The main CPU complex on an A10 (two big cores, two small cores, and L2, is maybe 15 mm^2.ARM STILL seems to be optimizing for core area, and then spending that same core area anyway in octacores and decacores. It makes no sense to me.
Obviously part of it is that Apple must be throwing a huge number of engineers at the problem. But that's not enough; there has to be some truly incredible project management involved to keep all those different teams in sync, and I don't think anyone has a clue how they have done that.
They certainly don't seem to be suffering from any sort of "mythical man-month" Fred Brooks problems so far...
My personal suspicion is that, by luck or by hiring the best senior engineer in the world, they STARTED OFF at a place that is pretty much optimal for the trajectory they wanted.
They designed a good 3-wide core, then (as far as anyone can tell) converted that to a 6-wide core by clustering and (this is IMPORTANT) not worrying about all the naysayers who said that a very wide core could not be clocked very high.
Once they had the basic 6-wide core in place, they've had a superb platform on top of which different engineers can figure out improved sub-systems and just slot them in when ready. So we had the FP pipeline redesigned for lower latency, we had an extra NEON functional unit added, we've doubtless had constant improvements to branch prediction, I-fetching, pre-fetching, cache placement and replacement; and so on --- but these are all (more or less) "easy" to optimize given a good foundation on which to build.
I suspect, also, that unlike some in the industry, they have been extremely open to new ideas from academia, so that there's an implementation turnaround time of maybe two years or so from encountering a good idea (say a new design for a cluster predictor) through simulating it to validate its value, to implementing it.
I'm guessing that management (again unlike most companies) is willing to entertain a constant stream of ideas (from engineers, from reading the literature, from talking to academics) and to ACCEPT and NOT COMPLAIN about the cost of writing the simulations, in the full understanding that only 5 or 10% of simulated ideas are worth emulating. My guess is that they've managed to increase frequency rapidly (in spite of the 6-wide width) by implementing a constant stream of the various ideas that have been published (and generally mocked or ignored by the industry) for ways to scale things like load-store queues, issue, and rename --- the standard frequency/power pain-points in OoO design.
Meanwhile ARM seems to suffer from terminal effort-wasting. Apple has a great design, which they have been improving every year. ARM's response, meanwhile, has been to hop like a jack rabbit from A57 to A72 to A73, with no obvious conceptual progression. If each design spends time revising basics like the decoder and the optimal pipeline width, there's little time left to perform the huge number of experiments that I think Apple perform to keep honing the branch predictors, the instruction fusion, the pre-fetchers, and so on.
It reminds me of a piece of under-appreciated software, namely Mathematica, which started off with a ridiculously good foundation and horrible performance. But because the foundation was so good, every release had to waste very little time re-inventing the wheel, it could just keep adding and adding, until the result is just unbelievable.
Meteor2 - Wednesday, March 15, 2017 - link
Didn't Jim Keller have something to do with their current architecture?And yes, Apple seems to have excellent project management. Really, they have every stage of every process nailed. They're not the biggest company in the world by accident.
Meteor2 - Wednesday, March 15, 2017 - link
Also don't forget that (like Intel) ARM has multiple design teams. A72 and A73 are from separate teams; from that perspective, ARM's design progression does make sense. The original A73 'deepdive' by Andrei explained it very well.name99 - Wednesday, March 15, 2017 - link
This is a facet of what I said about project management.The issue is not WHY there are separate CPU design teams --- no-one outside the companies cares about the political compromises that landed up at that point.
The issue is --- are separate design teams and restarting each design from scratch a good fit to the modern CPU world?
It seems to me that the answer has been empirically answered as no, and that every company that follows this policy (which seem to include IBM, don't know about QC or the GPU design teams) really ought to rethink. We don't recreate compilers, or browsers, or OS's every few years from scratch, but we seem to have taken it for granted that doing so for CPUs made sense.
I'm not sure this hypothesis explains everything --- no-one outside Apple (and few inside) have the knowledge necessary to answer the question. But I do wonder if the biggest part of Apple's success came from their being a SW company, and thus looking at CPU design as a question of CONSTANTLY IMPROVING a good base, rather than as a question of re-inventing the wheel every few years the way the competition has always done things.
Meteor2 - Wednesday, March 15, 2017 - link
Part of having separate teams is to engender competition; another is to hedge bets and allow risk-taking. Core replacing Netburst is the standard example, I suppose. I'm sure there are others but they aren't coming to mind at the moment... Does replacing Windows CE with Windows 10 count?Meteor2 - Wednesday, March 15, 2017 - link
Methinks it's more to do with Safari having some serious optimisations for browser benchmarks baked in deep.I'd like to see the A10 subjected to GB4 and SpecInt.
name99 - Wednesday, March 15, 2017 - link
The A10 GeekBench numbers are hardly secret. Believe me, they won't make you happy.SPEC numbers, yeah, we're still waiting on those...
name99 - Wednesday, March 15, 2017 - link
Here's an example:https://browser.primatelabs.com/v4/cpu/959859
Summary:
Single-Core Score 3515
Crypto Score 2425
Integer Score 3876
Floating Point Score 3365
Memory Score 3199
The even briefer summary is that basically every sub-benchmark has A10 at 1.5x to 2x the Kirin 960 score. FP is even more brutal with some scores at 3x, and SGEMM at ~4.5x.
(And that's the A10... The A10X will likely be out within a month, likely fabbed on TSMC 10nm, likely an additional ~50% faster...)
Meteor2 - Wednesday, March 15, 2017 - link
Thanks. Would love to see those numbers in Anandtech charts, and normalised for power.