Supermicro's Twin: Two nodes and 16 cores in 1U
by Johan De Gelas on May 28, 2007 12:01 AM EST- Posted in
- IT Computing
Network Load Balancing
It is pretty clear that we can not test the Supermicro 1U Twin in a conventional manner. Testing one node alone doesn't make sense: who care if it is 1-2% faster or slower than a typical Intel 5000p chipset based server? So we decided to use Windows 2003 Network Load Balancing or software load balancing. NLB is used mostly for splitting the load of heavy web-based traffic over several servers to improve response times, throughput and more importantly, availability. Each node sends a heartbeat signal. If a host fails and stops emitting heartbeats, the other nodes will remove it from their NLB cluster information, and although a few seconds of network traffic will be lost, the website remains available. What is even better is the fact that NLB, due to the relatively simple distributed filtering algorithm on each node, puts very little load on the CPUs of the node. The heartbeat messages also consume very little bandwidth. Testing with a fast Ethernet switch instead of our usual Gigabit Ethernet switch didn't result in any significant performance loss, whether we talk about response time (ms) or throughput (URLs served per second).
With four and up to eight CPUs per node, it takes a while before the NLB cluster becomes fully loaded, as you can see at the picture below.

Web server measurements are a little harder to interpret than other tests, as you always have two measurements: response time and throughput. Theoretically, you could set a "still acceptable" maximum response time and measure how many requests the system can respond to without breaking this limit. However, in reality it is almost impossible to test this way, as we simulate a number of simultaneous users which send requests and then measure both response time and throughput. Each simultaneous user takes about one second to send a new request. Notice that the number of simultaneous user is not equal to the total number of users. One hundred simultaneous users may well mean that there are 20 users constantly clicking to get new information while 240 others are clicking and typing every 3 seconds.
Another problem is of course that in reality you never want your web server to be at 100% CPU load. For our academic research, we track tens of different parameters, including CPU load. For a report such as this one, this would mean however that you have to wade through massive tables to get an idea how the different systems compare. Therefore, we decide to pick out a request rate at which all systems where maxed out, to give an idea of the maximum throughput and the associated latency. In the graphics below, 200 simultaneous users torture the MCS web application requesting one URL every second.
The single node tests are represented by the lightly colored graphs, the darker graphs represent our measurement in NLB mode (2 nodes). We were only able to get four Xeon E5320 (quad core 1.86 GHz Intel Core architecture) processors for this article, unfortunately; it would have been nice to test with various other CPUs in 4-way configurations, but sometimes you have to take what you can get.
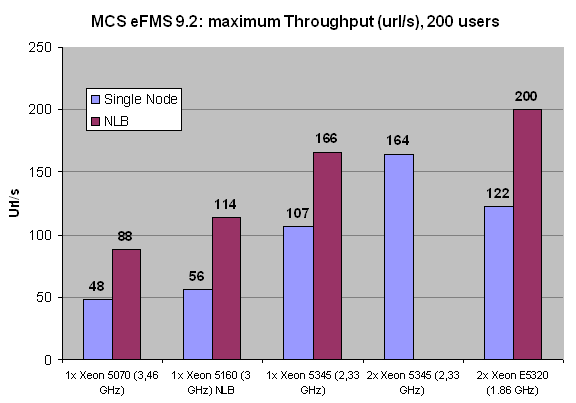
Notice that two CPUs connected by NLB and thus Gigabit Ethernet are not slower than two CPUs connected by the FSB. In other words, two nodes with one CPU per node are not slower than two CPUs in a single node. The most likely explanation is that the overhead of communicating over a TCP/IP Ethernet connection is offset by the higher amount of bandwidth that each CPU in the node has available. From the numbers above we may conclude that NLB scales very well: adding a second node increases the throughput by 60 to 100%. Scaling decreases as we increase the CPU power and the number of cores which is no surprise, as the latency of the Gigabit connection between the nodes starts to become more important. To obtain better scaling, we would probably have to use an InfiniBand connection but for this type of application that seems a bit like overkill.
Also note that 200 users means 200 simultaneous users which may translate - depending on the usage model of the client - to a few thousands of real active users in a day. The only configuration that can sustain this is the NLB configuration: in reality it could serve about 225 simultaneous users at one URL/s, but as we only asked for 200, it served up 200.
To understand this better, let us see what the corresponding response time is. Remember that this is not the typical response time of the application, but the response you get from an overloaded server. Only the 16 Xeon E5320 cores were capable of delivering more than 200 URL/s (about 225), while the other configurations had to work with a backlog.
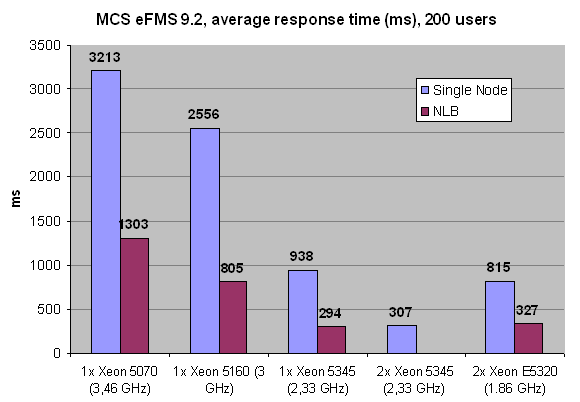
It is a bit extreme, but it gives a very good idea of what happens if you overload a server: response times increase almost exponentially. When we tested with 100 users, our dual Xeon E5320 (1.86 GHz, four cores in one node) provided a response time of about 120 ms on average per URL - measured across about 40 different URLs - and so did the same configuration in NLB (two nodes). A Xeon 5160 in each node in NLB responded in 145 ms, as the demanded throughput was much closer to its maximum of 114 ms. Now take a look at the measured response times at 200 URL/s.
The Xeon Dempsey 5070 (dual core 3.46 GHz 2MB NetBurst architecture) is only capable of sustaining half the user requests we demand from it, and the result is a 10X higher response time than our two node 16 core NLB server, or almost 30X higher than the minimum response time. Our quad Xeon 1.86 in NLB was capable of a response time of 327 ms, almost 3X higher than the lowest measured response time at 100 URL/s. So we conclude that pushing a web server to 90% of its maximum will result in a ~3X higher response time. This clearly shows that you should size your web server to work at about 60%, and no peak should go beyond 90%. Overload your web server with twice the traffic it can handle, and you'll be "rewarded" with response times that get 30X higher than the minimum necessary response time.
It is pretty clear that we can not test the Supermicro 1U Twin in a conventional manner. Testing one node alone doesn't make sense: who care if it is 1-2% faster or slower than a typical Intel 5000p chipset based server? So we decided to use Windows 2003 Network Load Balancing or software load balancing. NLB is used mostly for splitting the load of heavy web-based traffic over several servers to improve response times, throughput and more importantly, availability. Each node sends a heartbeat signal. If a host fails and stops emitting heartbeats, the other nodes will remove it from their NLB cluster information, and although a few seconds of network traffic will be lost, the website remains available. What is even better is the fact that NLB, due to the relatively simple distributed filtering algorithm on each node, puts very little load on the CPUs of the node. The heartbeat messages also consume very little bandwidth. Testing with a fast Ethernet switch instead of our usual Gigabit Ethernet switch didn't result in any significant performance loss, whether we talk about response time (ms) or throughput (URLs served per second).
With four and up to eight CPUs per node, it takes a while before the NLB cluster becomes fully loaded, as you can see at the picture below.
Web server measurements are a little harder to interpret than other tests, as you always have two measurements: response time and throughput. Theoretically, you could set a "still acceptable" maximum response time and measure how many requests the system can respond to without breaking this limit. However, in reality it is almost impossible to test this way, as we simulate a number of simultaneous users which send requests and then measure both response time and throughput. Each simultaneous user takes about one second to send a new request. Notice that the number of simultaneous user is not equal to the total number of users. One hundred simultaneous users may well mean that there are 20 users constantly clicking to get new information while 240 others are clicking and typing every 3 seconds.
Another problem is of course that in reality you never want your web server to be at 100% CPU load. For our academic research, we track tens of different parameters, including CPU load. For a report such as this one, this would mean however that you have to wade through massive tables to get an idea how the different systems compare. Therefore, we decide to pick out a request rate at which all systems where maxed out, to give an idea of the maximum throughput and the associated latency. In the graphics below, 200 simultaneous users torture the MCS web application requesting one URL every second.
The single node tests are represented by the lightly colored graphs, the darker graphs represent our measurement in NLB mode (2 nodes). We were only able to get four Xeon E5320 (quad core 1.86 GHz Intel Core architecture) processors for this article, unfortunately; it would have been nice to test with various other CPUs in 4-way configurations, but sometimes you have to take what you can get.
Notice that two CPUs connected by NLB and thus Gigabit Ethernet are not slower than two CPUs connected by the FSB. In other words, two nodes with one CPU per node are not slower than two CPUs in a single node. The most likely explanation is that the overhead of communicating over a TCP/IP Ethernet connection is offset by the higher amount of bandwidth that each CPU in the node has available. From the numbers above we may conclude that NLB scales very well: adding a second node increases the throughput by 60 to 100%. Scaling decreases as we increase the CPU power and the number of cores which is no surprise, as the latency of the Gigabit connection between the nodes starts to become more important. To obtain better scaling, we would probably have to use an InfiniBand connection but for this type of application that seems a bit like overkill.
Also note that 200 users means 200 simultaneous users which may translate - depending on the usage model of the client - to a few thousands of real active users in a day. The only configuration that can sustain this is the NLB configuration: in reality it could serve about 225 simultaneous users at one URL/s, but as we only asked for 200, it served up 200.
To understand this better, let us see what the corresponding response time is. Remember that this is not the typical response time of the application, but the response you get from an overloaded server. Only the 16 Xeon E5320 cores were capable of delivering more than 200 URL/s (about 225), while the other configurations had to work with a backlog.
It is a bit extreme, but it gives a very good idea of what happens if you overload a server: response times increase almost exponentially. When we tested with 100 users, our dual Xeon E5320 (1.86 GHz, four cores in one node) provided a response time of about 120 ms on average per URL - measured across about 40 different URLs - and so did the same configuration in NLB (two nodes). A Xeon 5160 in each node in NLB responded in 145 ms, as the demanded throughput was much closer to its maximum of 114 ms. Now take a look at the measured response times at 200 URL/s.
The Xeon Dempsey 5070 (dual core 3.46 GHz 2MB NetBurst architecture) is only capable of sustaining half the user requests we demand from it, and the result is a 10X higher response time than our two node 16 core NLB server, or almost 30X higher than the minimum response time. Our quad Xeon 1.86 in NLB was capable of a response time of 327 ms, almost 3X higher than the lowest measured response time at 100 URL/s. So we conclude that pushing a web server to 90% of its maximum will result in a ~3X higher response time. This clearly shows that you should size your web server to work at about 60%, and no peak should go beyond 90%. Overload your web server with twice the traffic it can handle, and you'll be "rewarded" with response times that get 30X higher than the minimum necessary response time.








28 Comments
View All Comments
SurJector - Tuesday, June 5, 2007 - link
I've just reread your article. I'm a little bit surprised by the power:idle load
1 node : 160 213
2 nodes: 271 330
increase: 111 117
There is something wrong: the second node adds only 6W (5.5W counting efficiency) of power consumption ?
Could it be that some power-saving options are not set on the second node (speedstep, or similar) ?
Nice article though, I bet I'd love to have a rack of them for my computing farm. Either that or wait (forever ?) for the Barcelona equivalents (they should have better memory throughput).
Super Nade - Saturday, June 2, 2007 - link
Hi,The PSU is built by Lite-On. I owned the PWS-0056 and it was built like a tank. Truely server grade build quality.
Regards,
Super Nade, OCForums.
VooDooAddict - Tuesday, May 29, 2007 - link
Here are the VMWare ESX issues I see. ... They basically compound the problem.- No Local SAS controller. (Already mentioned)
- No Local SAS requires booting from a SAN. This means you will use your only PCIe slot for a SAN Hardware HBA as ESX can't boot with a software iSCSI.
- Only Dual NICs on board and with the only expansion slot taken up by the SAN HBA (Fiber Channel or iSCSI) you already have a less then ideal ESX solution. --- ESX works best with a dedicated VMotion port, Dedicated Console Port, and at least one dedicated VM port. Using this setup you'll be limited to a dedicated VMotion and a Shared Console and VM Port.
The other issue is of coarse the non redundant power supply. While yes ESX has a High Availability mode where it restarts VMs from downed hardware. It restarts VMs on other hardware, doesn't preserve them. You could very easily loose data.
Then probably the biggest issue ... support. Most companies dropping the coin on ESX server are only going to run it on a supported platform. With supported platforms from the Dell, HP and IBM being comparatively priced and the above issues, I don't see them winning ANY of the ESX server crowd with this unit.
I could however see this as a nice setup for the VMWare (free) Virtual Server crowd using it for virtualized Dev and/or QA environments where low cost is a larger factor then production level uptime.
JohanAnandtech - Wednesday, May 30, 2007 - link
Superb feedback. I feel however that you are a bit too strict on the dedicated ports. A dedicated console port seems a bit exagerated, and as you indicate a shared Console/vmotion seems acceptable to me.DeepThought86 - Monday, May 28, 2007 - link
I thought it interesting to note how poor the scaling was on the web server benchmark when going from 1S to 2S 5345 (107 URL's/s to 164). However the response times scaled quite well.Going from 307 ms to 815 ms (2.65) with only a clockspeed difference of 2.33 cs 1.86 (1.25) is completely unexpected. Since the architecture is the same, how can a 1.25 factor in clock lead to a 2.65 factor in performance? Then I remembered you're varying TWO factors at once making it impossible to compare the numbers.... how dumb is that in benchmark testing??
Honestly, it seems you guys know how to hook up boxes but lack the intelligence to actually select test cases that make sense, not to mention analyse your results in a meaningful way
It's also a pity you guys didn't test with the AMD servers to see how they scaled. But I guess the article is meant to pimp Supermicro and not point out how deficient the Intel system design is when going from 4-cores to 8
JohanAnandtech - Tuesday, May 29, 2007 - link
I would ask you to read my comments again. Webserver performance can not be measured by one single metric unless you can keep response time exactly the same. In that case you could measure throughput. However in the realworld, response time is never the same, and our test simulates real users. The reason for this "superscaling" of responstimes is that the slower configurations have to work with a backlog. Like it or not, but that is what you see on a webserver.
We have done that already here for a number of workloads:
http://www.anandtech.com/cpuchipsets/intel/showdoc...">http://www.anandtech.com/cpuchipsets/intel/showdoc...
This article was about introducing our new benches, and investigating the possibilities of this new supermicro server. Not every article can be an AMD vs Intel article.
And I am sure that 99.9% of the people who will actually buy a supermicro Twin after reading this review, will be very pleased with it as it is an excellent server for it's INTENDED market. So there is nothing wrong with giving it positive comments as long as I show the limitations.
TA152H - Tuesday, May 29, 2007 - link
Johan,I think it's even better than you didn't bring into the AMD/Intel nonsense, because it tends to take focus away from important companies like Supermicro. A lot of people aren't even aware of this company, and it's an extremely important company that makes extraordinary products. Their quality is unmatched, and although they are more expensive, it is excellent to have the option of buying a top quality piece. It's almost laughable, and a bit sad, when people call Asus top quality, or a premium brand. So, if nothing else, you brought an often ignore company into people's minds. Sadly, on a site like this where performance is what is generally measured, if you guys reviewed the motherboards, it would appear to be a mediocre, at best product. So, your type of review helps put things in their proper perspective; they are a very high quality, reliable, innovative company that is often overlooked, but has a very important role in the industry.
Now, having said that (you didn't think I could be exclusively complimentary, did you?), when are you guys going to evaluate Eizo monitors??? I mean, how often can we read articles on junk from Dell and Samsung, et al, wondering what the truly best monitors are like? Most people will buy mid-range to low-end (heck, I still buy Samsung monitors and Epox motherboards sometimes because of price), but I also think most people are curious about how the best is performing anyway. But, let's give you credit where it's due, it was nice seeing Supermicro finally get some attention.
DeepThought86 - Monday, May 28, 2007 - link
Also, looking at your second benchmark I'm baffled how you didn't include a comparison of 1xE5340 vs 2x5340 or 1x5320 vs 2x5320 so we could see scaling. You just have a comparison of Dual vs 2N, where (duh!) the results are similar.Sure, there's 1x5160 vs 2x5160 but since the number of cores is half we can't see if memory performance is a bottleneck. Frankly, if Intel had given you instruction on how to explicitly avoid showing FSB limitations in server application they couldn't have done a better job.
Oh wait, looks like 2 Intel staffers helped on the project! BIG SURPRISE!
yacoub - Monday, May 28, 2007 - link
http://images.anandtech.com/reviews/it/2007/superm...">http://images.anandtech.com/reviews/it/2007/superm...Looks like the top DIMM is not fully seated? :D
MrSpadge - Monday, May 28, 2007 - link
Nice one.. not everyone would catch such a fault :)MrS