Intel's newest Quad Xeon MP versus HP's DL585 Quad Opteron
by Johan De Gelas on November 10, 2006 12:00 PM EST- Posted in
- IT Computing
SPECjbb2005
SPECjbb2005 from SPEC (Standard Performance Evaluation Corporation) evaluates the performance of server side Java by emulating a three-tier client/server system with emphasis on the middle tier. Instead of testing with a possible disk intensive database system, SPECjbb uses tables of objects, implemented by Java Collections, rather than a separate database. The SPECjbb score thus depends on:
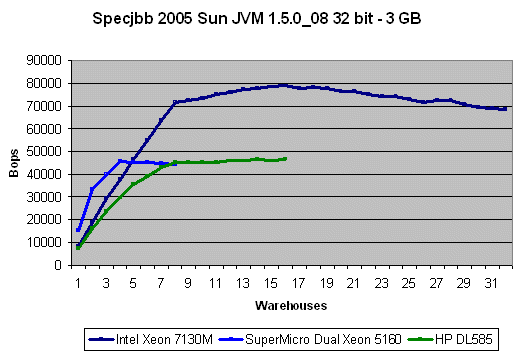
Performance on the quad Opteron machine is absolutely horrible: the dual Xeon DP 5160 is only a few percent slower than our quad Opteron. As SPECjbb is very memory sensitive we suspected that the NUMA architecture of the Opteron might be influencing the result. The scaling numbers confirmed our assumption: the dual Opteron scored only 48% lower, while we expect a 70% increase from 2 extra cores.
In many cases you would like to run several Java applications on one server with or without virtualization, especially on quad socket machines. Therefore we also tested SPECjbb with four application instances. Using NUMActl, a clever utility written by Andi Kleen, we were able to bind each Java application to one CPU node on the HP DL585.
On the Opteron we used:
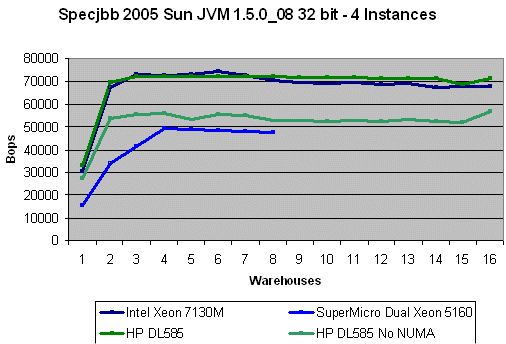
If we let Linux manage the four instances, performance increases about 16% compared to using one instance. If we force each instance to stay on one node (one CPU + memory), performance increases spectacularly by 56%! So it seems that it is rather hard for the Linux kernel to keep the instances where they should be. This is good and bad news for AMD: it means that the Opteron 880 can compete with the more expensive Xeon MP, but it also means that the Opteron requires more "manual" optimization than the Xeon MP. The Xeon MP performs at the same level with 4 instances as it does with one.
We suspect that the Sun JVM is reasonably well optimized for the Opteron, and maybe a little bit less effort went into the Intel optimizations as Sun features mostly Opteron and Sparc servers. The BEA JRockit JDK provides a highly optimized JVM for running JAVA applications on the x86-64 and Itanium CPUs. We are still in the process of testing with this JVM, but it seems that the HP DL585 is capable of attaining 110,000 bops, the Supermicro Dual Xeon 5160 about 70 to 75,000 bops and the Tulsa system about 140,000 bops so far. We are trying to find out which tuning parameters are realistic and which ones are maybe a little too extreme. We'll report back soon with our findings, as we have another new server CPU to show you in the near future.
SPECjbb2005 from SPEC (Standard Performance Evaluation Corporation) evaluates the performance of server side Java by emulating a three-tier client/server system with emphasis on the middle tier. Instead of testing with a possible disk intensive database system, SPECjbb uses tables of objects, implemented by Java Collections, rather than a separate database. The SPECjbb score thus depends on:
- The JVM (Java Virtual Machine) and the way the JVM is tuned
- CPU processing power
- Caching and memory speed
- Multiprocessing configuration (Scalability)
"SPECjbb2005 is a follow-on release to SPECjbb2000, which was inspired by the TPC-C benchmark and loosely follows the TPC-C specification for its schema, input generation, and transaction profile. SPECjbb2005 runs in a single JVM in which threads represent terminals, where each thread independently generates random input before calling transaction specific logic. There is neither network nor disk IO in SPECjbb2005."SPECjbb starts up to two threads per core. For example, with Hyper-Threading enabled on our 8 core quad CPU Xeon MP 7030M system, 32 threads were started on the 16 logical CPUs. Each thread is a warehouse. Again from SPEC.org:
"A warehouse is a unit of stored data. It contains roughly 25MB of data stored in many objects in several Collections (HashMaps, TreeMaps). A thread represents an active user posting transaction requests within a warehouse. There is a one-to-one mapping between warehouses and threads, plus a few threads for SPECjbb2005 main and various JVM functions. As the number of warehouses increases during the full benchmark run, so does the number of threads. A "point" represents the throughput during the measurement interval at a given number of warehouses. A full benchmark run consists of a sequence of measurement points with an increasing number of warehouses (and thus an increasing number of threads)"First we tested with some decent but rather generic tuning that we could use on all systems. The JVM was Sun's, version 1.5.0_08.
java -classpath jbb.jar:check.jar -Xms3072m -Xmx3072m -Xmn1024m -Xss128k -XX:+AggressiveOpts -XX:+UseParallelOldGC -XX:+UseParallelGC spec.jbb.JBBmain -propfile SPECjbb.propsPerformance on the quad Opteron machine is absolutely horrible: the dual Xeon DP 5160 is only a few percent slower than our quad Opteron. As SPECjbb is very memory sensitive we suspected that the NUMA architecture of the Opteron might be influencing the result. The scaling numbers confirmed our assumption: the dual Opteron scored only 48% lower, while we expect a 70% increase from 2 extra cores.
In many cases you would like to run several Java applications on one server with or without virtualization, especially on quad socket machines. Therefore we also tested SPECjbb with four application instances. Using NUMActl, a clever utility written by Andi Kleen, we were able to bind each Java application to one CPU node on the HP DL585.
On the Opteron we used:
numactl -cpubind=(1-4) -membind=(1-4) java -classpath jbb.jar:check.jar -Xms3072m -Xmx3072m -Xmn1024m -Xss128k -XX:+AggressiveOpts -XX:+UseParallelOldGC -XX:+UseParallelGC spec.jbb.JBBmain -propfile SPECjbb.props -id (1-4)java -classpath jbb.jar:check.jar -Xms3072m -Xmx3072m -Xmn1024m -Xss128k -XX:+AggressiveOpts -XX:+UseParallelOldGC -XX:+UseParallelGC spec.jbb.JBBmain -propfile SPECjbb.props -id (1 to 4)If we let Linux manage the four instances, performance increases about 16% compared to using one instance. If we force each instance to stay on one node (one CPU + memory), performance increases spectacularly by 56%! So it seems that it is rather hard for the Linux kernel to keep the instances where they should be. This is good and bad news for AMD: it means that the Opteron 880 can compete with the more expensive Xeon MP, but it also means that the Opteron requires more "manual" optimization than the Xeon MP. The Xeon MP performs at the same level with 4 instances as it does with one.
We suspect that the Sun JVM is reasonably well optimized for the Opteron, and maybe a little bit less effort went into the Intel optimizations as Sun features mostly Opteron and Sparc servers. The BEA JRockit JDK provides a highly optimized JVM for running JAVA applications on the x86-64 and Itanium CPUs. We are still in the process of testing with this JVM, but it seems that the HP DL585 is capable of attaining 110,000 bops, the Supermicro Dual Xeon 5160 about 70 to 75,000 bops and the Tulsa system about 140,000 bops so far. We are trying to find out which tuning parameters are realistic and which ones are maybe a little too extreme. We'll report back soon with our findings, as we have another new server CPU to show you in the near future.








88 Comments
View All Comments
duploxxx - Monday, November 13, 2006 - link
Its nice to say that the new Intel system's have the RAS support and the AMD one not, however keep in mind that you are using an old opteron socket (you can say you have the latest revision 2006).AMD's Opteron 800/200-series (1207-pin, Socket F). The 1207-pin Socket F "Santa Rosa" core AMD Opteron CPU features DDR-2 memory support and Virtualization technology, in addition to Memory RAS security.
Slappi - Sunday, November 12, 2006 - link
Please sell your Intel stock and then rewrite the article please.Thank you,
Slappi
LuxFestinus - Tuesday, November 14, 2006 - link
Taken from Scientia's post here:http://www.amdzone.com/index.php?name=PNphpBB2&...">AMD Forum Board
Kiijibari - Sunday, November 12, 2006 - link
They are misleading as it is unclear what you mean with "mem bandwidth".Is it FSB bandwidth ? System memory bandwidth ? CPU bandwidth ... ?
It is correct that Intel can deliver 21 GB/s from the memory, however one CPU so far can "just" can handle ~11GB/s. So why should 1 Xeon DP have a memory bandwidth of 21 GB/s ? That statement is not valid, if you limit it to one CPU.
Obviously, you meant the System memory bandwidth, but then I really wonder about your Opteron Socket-F numbers ...
First it would be only fair to write the system bandwidth for a 2P System(or whatever compares to the Intel configuration), too. This would be then ~21 GB/s, too, for a 2P Opteron System, 42 GB/s for a Quad System.
Then I wonder how you calculate that 8.5 GB/s mentioned with the Socket-F Opterons.
As far as I know, these chips support DDR2-667 and that means 10.6 GB/s, not 8.5. Please be fair and correct at least that obvious error ...
cheers
Kiijibari
spaceoddity - Saturday, November 11, 2006 - link
Hi Johan,Thank you very much for doing some Linux benchmarks. They are not easy to come by. There are virtually no Linux benchmarks for desktops (perhaps understandable, but frustrating for us Linux users), but for servers, which is where Linux has a sizeable presence, they are always welcome. I hope Anandtech continues to provide good Linux/UNIX benchmarks, and doesn't abandon them for more windoze benchmarks, which are everywhere anyway.
Cheers!
JohanAnandtech - Sunday, November 12, 2006 - link
Well I firmly believe the marketshare of linux servers can only grow and that therefore linux benchmarking will only get more important. A colleague of mine pointed out that Novell has launched e-directory: a very solid alternative to MS Small business server with the same functionality and ease of use, but much cheaper per connection, and with the ability to grow with the enterprise.It is just yet another reason why Linux on servers is so attractive besides much lower cost and much more control over your own IT infrastructure
Justin Case - Saturday, November 11, 2006 - link
In the OpenSSL 1024-bit signs, the quad Opteron has an almost 40% advantage over the Xeon when using 8 threads (in fact, that advantage rises to more than 90% when using optimized binaries), and is still the best of the bunch at 16 threads (32 wasn't tested), and yet the article text completely fails to mention this.It mentions the point where the (more expensive and more power-hungry) Xeon has its biggest advantage (4 threads, with a whooping 9% advantage over the Opteron), and the point where the Sun server (even more expensive) has its biggest advantage (32 threads, but the Opteron wins if using optimized binaries), but completely ignores the Opteron's trouncing of all the competition at 8 and 16 threads, and the fact that the Xeon 5160 cannot scale past its 4-thread peformance at all.
http://images.anandtech.com/reviews/it/2006/tulsa-...">http://images.anandtech.com/reviews/it/2006/tulsa-...
So the fact is the Opteron can handle a load of 10000 signs per second (over 12000 with optimized binaries), while the Xeon can't even reach 6000 (6200 with optimized binaries).
http://images.anandtech.com/reviews/it/2006/woodcr...">http://images.anandtech.com/reviews/it/...rest-lin...
And yet, according to the article, "the Opteron no longerbeats the Xeon". Huh? A 40% advantage isn't enough to win? Who compared the scores, Diebold?
So what if the Xeon performs better when you cripple the Opteron by reducing the number of threads? In any real-world situation, the server admin is going to use the number of threads that delivers the best performance (and is going to use the optimized binaries, of course, if he's competent). Just because the Xeon tops out at 4 threads doesn't mean the (better) results delivered by the Opteron should be discarded.
If this was a "normal" Anadtech article, I wouldn't be surprised by the bias and "selective reporting", but I never expected Johan to "tow the party line" like this.
JohanAnandtech - Sunday, November 12, 2006 - link
From the article:Yeah, I am really doing Intel a favor here, pointing out one of the weaknesses of their core architecture and showing yet another very weak point of Netburst.
Again from the article:
More than one thread per core doesn't give any performance advantage (unless you have a multithreaded CPU) so of course a Dual Xeon 5160 doesn't scale beyond 4 threads, just like a Dual Opteron. As openSSL scales almost perfectly, The important thing here is performance/core, as you don't want to pay for multi socket machine if you don't want to.
You should definitely read more carefully. "Selective reporting" would not include the MySQL, Power consumption or even the NUMA specjbb results as they are favorable for the Opteron.
Justin Case - Monday, November 13, 2006 - link
The fact is, the quad Opteron box reviewed (DL585) _can_ sustain higher performance than the Xeon 5160 (close to 90% higher, using optimized binaries), correct? So, unless the Opteron box costs twice as much as the 5160 box (identically supported and configured, apart from the CPUs / MB), it delivers more bang for the buck.Is this a server test or a CPU core test? It's filed under "IT / Computing", not under "CPU / Chipset", so I have to assume it's supposed to be the former.
So what if one server has twice (or 100 times) as many cores as the other? You might as well argue that the servers must be compared at the same clock speed, with the same amount of on-die cache, or with the same type of memory. All those things might be relevant when comparing CPU architectures (then again...), but not when you're comparing complete systems. The whole point of a server comparison is to see what kind of performance you get for the price. If one server is 70% more expensive but 80% faster, it's still a better deal for people who need the extra performance. That extra performance can be due to a higher clock speed, more CPUs, more cores per CPU, better memory bandwidth, a dedicated coprocessor, magic imps, whatever. But it doesn't make any sense to "compensate" for those variables (or for one of those variables) and ignore the fact that server X can and does deliver better performance than server Y when both make full use of their resources.
At 4 threads, the 5160 is the fastest system of those tested. So what if it has a 20% clock speed advantage? It's still the fastest, right? You're not going to artificially cripple its clock speed to match the others; doing that wouldn't make any sense (because, in the real world, no buyer / server admin would do that). So why cripple the other systems by limiting the number of threads they are running? In that test (with unoptimized binaries), the Sun box reaches the highest performance, period. With optimized binaries, the Opteron box manages to pull slightly ahead. Of course, then you have to take price into account, and maybe for a lot of people the 5160-based server will be the better deal, but you can't say it performs better when, objectively, it does not.
nah - Saturday, November 11, 2006 - link
Great job Johan---as always