AMD Opteron vs. Intel Xeon: Database Performance Shootout
by Anand Lal Shimpi, Jason Clark & Ross Whitehead on March 2, 2004 2:11 AM EST- Posted in
- IT Computing
FSB Impact on Performance
We've alluded to FSB bandwidth being a fundamental limitation in Intel's
multiprocessor architecture, and now we're here to address the issue
a bit further.
A major downside to Intel's reliance on an external North Bridge is that
it becomes very expensive to implement multiple high speed FSB interfaces as
well as a difficult engineering problem to solve once you grow beyond 2-way configurations.
Unfortunately Intel's solution isn't a very elegant one; regardless
of whether you're running 1, 2 or 4 Xeon processors they all share the
same 64-bit FSB connection to the North Bridge.
The following diagram should help illustrate the bottleneck:
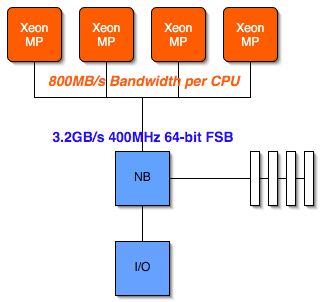
In the case of a 4-way Xeon MP system with a 400MHz FSB, each processor can be offered a maximum of 800MB/s of bandwidth to the North Bridge. If you try running a single processor Pentium 4 3.0GHz with a 400MHz FSB you'll note a significant performance decrease and that's while still giving the processor a full 3.2GB/s of FSB bandwidth; now if you cut that down to 800MB/s the performance of the processor would suffer tremendously.
It is because of this limitation that Intel must rely on larger on-die L3 caches to hide the FSB bottleneck; the more information that can be stored locally in the Xeon's on-die cache, the less frequently the Xeon must request for data to be sent over the heavily trafficked FSB.
What's even worse about this shared FSB is that the problem grows larger as you increase the number of CPUs and their clock speed. A 2-way Xeon system won't experience the negative effects of this FSB bottleneck as much as a 4-way Xeon MP; and a 4-way Xeon MP running at 3GHz will be hurting even more than a 4-way 2.0GHz Xeon MP. It's not a nice situation to be in, but there's nothing you can do to skirt the issue, which is where AMD's solution begins to appear to be much more appealing:
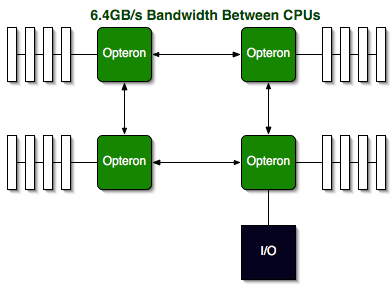
First remember that each Opteron has its own on-die North Bridge and memory controller, so there are no external chipsets to deal with. Each Opteron CPU features three point-to-point Hyper Transport links, delivering 3.2GB/s of bandwidth in each direction (6.4GB/s full duplex). The advantage is clear: as you scale the number of CPUs in an Opteron server there are no FSB bottlenecks to worry about. Scalability on the Opteron is king, which is the result of designing the platform first and foremost for enterprise level server applications.
Intel may be able to add 64-bit extensions to their Xeon MPs, but the performance bottlenecks that exist today will continue to plague the Xeon line until there's a fundamental architecture change.








58 Comments
View All Comments
Rand - Friday, May 20, 2005 - link
perlgreen - Tuesday, June 1, 2004 - link
Is there any chance that you guys could do more tests and benchmarking on Linux for IT Computing/Servers? I really like your site, but it'd be really nice if there would be more stuff for fans of the Penguin!cheers,
Campbell
ragusauce - Friday, March 5, 2004 - link
#54We have been building from source and trying different options / debug versions...
DBBoy - Friday, March 5, 2004 - link
#47 - In OLAP, or poorly indexed environments where the amount of data exceeds the 4 MB L3 cache of the Xeons the Opteron is going to shine even more with it's increased memory bandwidth.Assuming you do not bottleneck on the disk IO the SQL cache/RAM will be utilised much more thus putting more of a burden on the FSB of the Xeons in addition to allowing the Opteron's memory bandwidth to display it's abilities.
Jason Clark - Friday, March 5, 2004 - link
ragusauce, using binaries or building from source?Cheers
ragusauce - Friday, March 5, 2004 - link
We have been doing extensive testing of MySQL64 on Opteron and have had problems with seg faults as well.zarjad - Thursday, March 4, 2004 - link
Great, thanks.My thoughts:
In this type of application you are likely to use more than 4GB memory.
Memory bandwidth should matter because you will be doing a lot of full table scans (as opposed to using indexes).
Jason Clark - Thursday, March 4, 2004 - link
zarjad, I'll get back to you on that question I have some thoughts and amd discussing them with one of the guys that worked with us on the tests (Ross).zarjad - Thursday, March 4, 2004 - link
Jason, any comments on #47?Jason Clark - Wednesday, March 3, 2004 - link
The os used was windows 2003 enterprise which does indeed support NUMA. So NUMA was enabled.. this was covered in an earlier response.